Semantic search
Search that ranks by meaning and similarity (often embeddings) rather than exact keyword match, so "React front-end" can surface profiles that only say "UI engineer with hooks".
Michal Juhas · Last reviewed May 2, 2026
What is semantic search?
Semantic search ranks results by meaning and similar wording, not only by exact keywords. Two different job titles can still match when they describe the same kind of work.
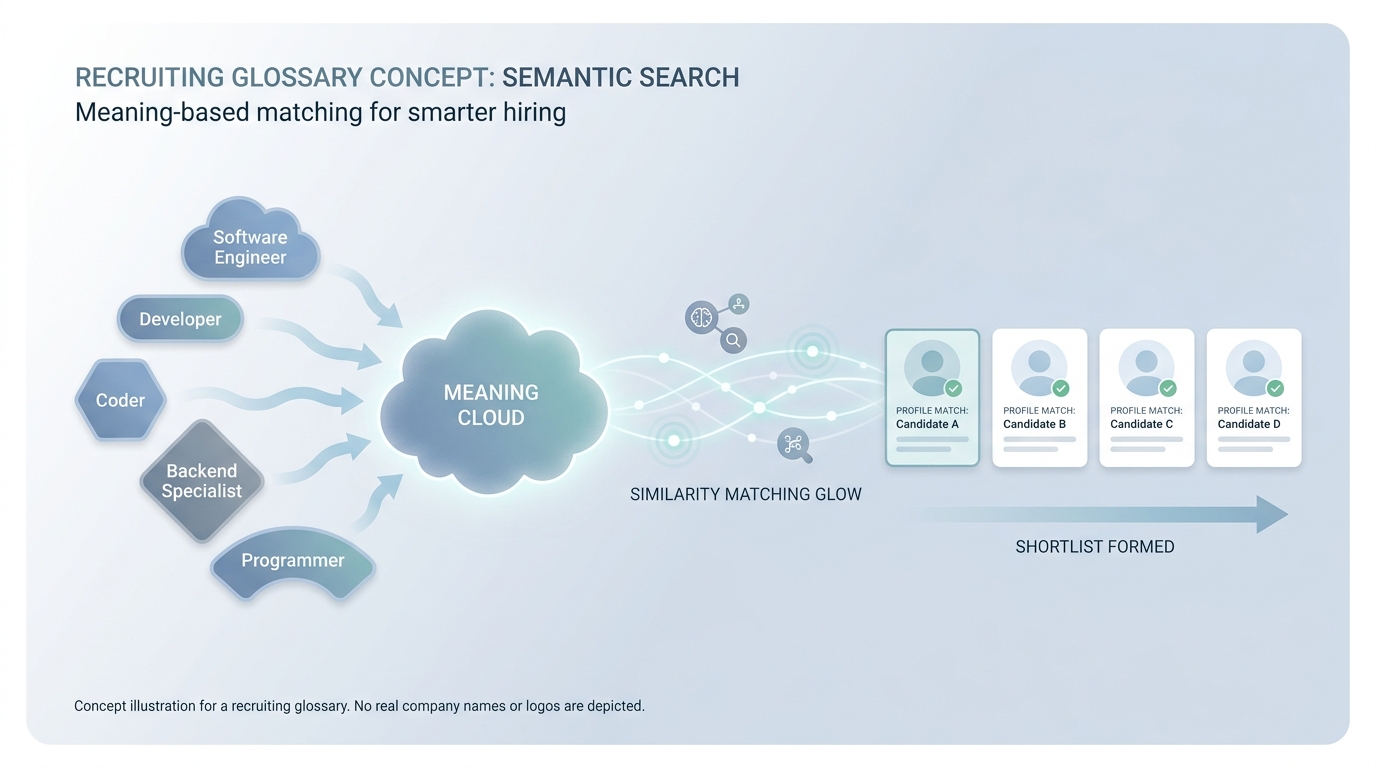
In practice
- Job boards show "jobs like this one" even when titles do not match word for word; that recommendation leans on meaning, like semantic search. Recruiters notice it when one portal surfaces "customer success" roles for an "account manager" search.
- Talent products market "AI matching" or "similar profiles" when they rank people by meaning instead of exact strings. You hear that language in vendor demos and in TA tool bake-offs.
- Sourcers say "this database gets synonyms better than literal LinkedIn search" when they explain why a shortlist surfaced different wording than they typed.
Quick read, then how hiring teams use it
This is for recruiters, sourcers, TA, and HR partners who need the same vocabulary in debriefs, vendor calls, and policy reviews. Skim the first section when you need a fast shared picture. Use the second when you are deciding how it shows up in the ATS, sourcing tools, or candidate communications.
Plain-language summary
- What it means for you: Semantic search finds "things like this" even when the words differ, like recommendations that know "customer success" is close to "account manager."
- How you would use it: You type a short job story, you scan suggestions, you still read profiles.
- How to get started: Run the same req twice: once with literals only, once with "similar" toggled on, compare who surfaces.
- When it is a good time: When Boolean gives zero or nonsense because titles are creative, not wrong.
When you are running live reqs and tools
- What it means for you: Semantic search maps text to vectors (or similar representations) for ranking and near-duplicate detection. Thin profiles and buzzwords still poison signals.
- When it is a good time: When sourcing automation APIs expose embeddings or "match" endpoints worth monitoring.
- How to use it: Pair with Boolean search slices for explainability, log vendor ranking changes.
- How to get started: Read Boolean search vs AI sourcing and build one hybrid workflow on paper.
- What to watch for: Black-box "AI matched" without receipts, and multilingual drift when English-only models rank non-English titles.
Where we talk about this
Sourcing automation conversations compare APIs versus "just prompting" for discovery. Semantic search sits in the API-heavy world: clean inputs, stable identifiers, monitoring when providers change ranking. We walk examples at Sourcing Lab.
Around the web (opinions and rabbit holes)
Third-party creators move fast. Treat these as starting points, not endorsements, and double-check anything before you wire candidate data.
YouTube
- What is semantic search? (Elasticsearch) is engineer-flavored but maps well to "meaning, not only keywords."
- Introduction to Large Language Models (Google Cloud Tech) explains embeddings-adjacent vocabulary executives hear.
- How to Use Boolean Search on LinkedIn pairs with semantic toggles many sourcers combine in practice.
- Is boolean search still big? in r/recruiting is the perennial literal-versus-semantic debate.
- How do you make a great Boolean search? in r/recruiting grounds hybrid workflows in reality.
- How is AI being used in your recruiting process? in r/recruiting includes semantic product experiences without the jargon.
Quora
- What is semantic search? is a broad explainer page (read critically).
Literal Boolean versus semantic
| Need | Prefer |
|---|---|
| Exact cert or employer string | Boolean |
| Synonyms and adjacent skills | Semantic |
| Explainable shortlist to legal | Boolean slice + human read |
Related on this site
- Blog: Boolean search vs AI sourcing
- Tools: ChatGPT
- Guides: Sourcers
- Live cohort: Sourcing Lab
- Deepening skills: Become a member