Talent data aggregators for sourcing
Platforms and APIs that compile candidate profile data from multiple public and licensed sources, such as LinkedIn, GitHub, job boards, and professional publications, into a unified searchable layer so sourcers can find and contact passive candidates without visiting each source manually.
Michal Juhas · Last reviewed May 4, 2026
What are talent data aggregators for sourcing?
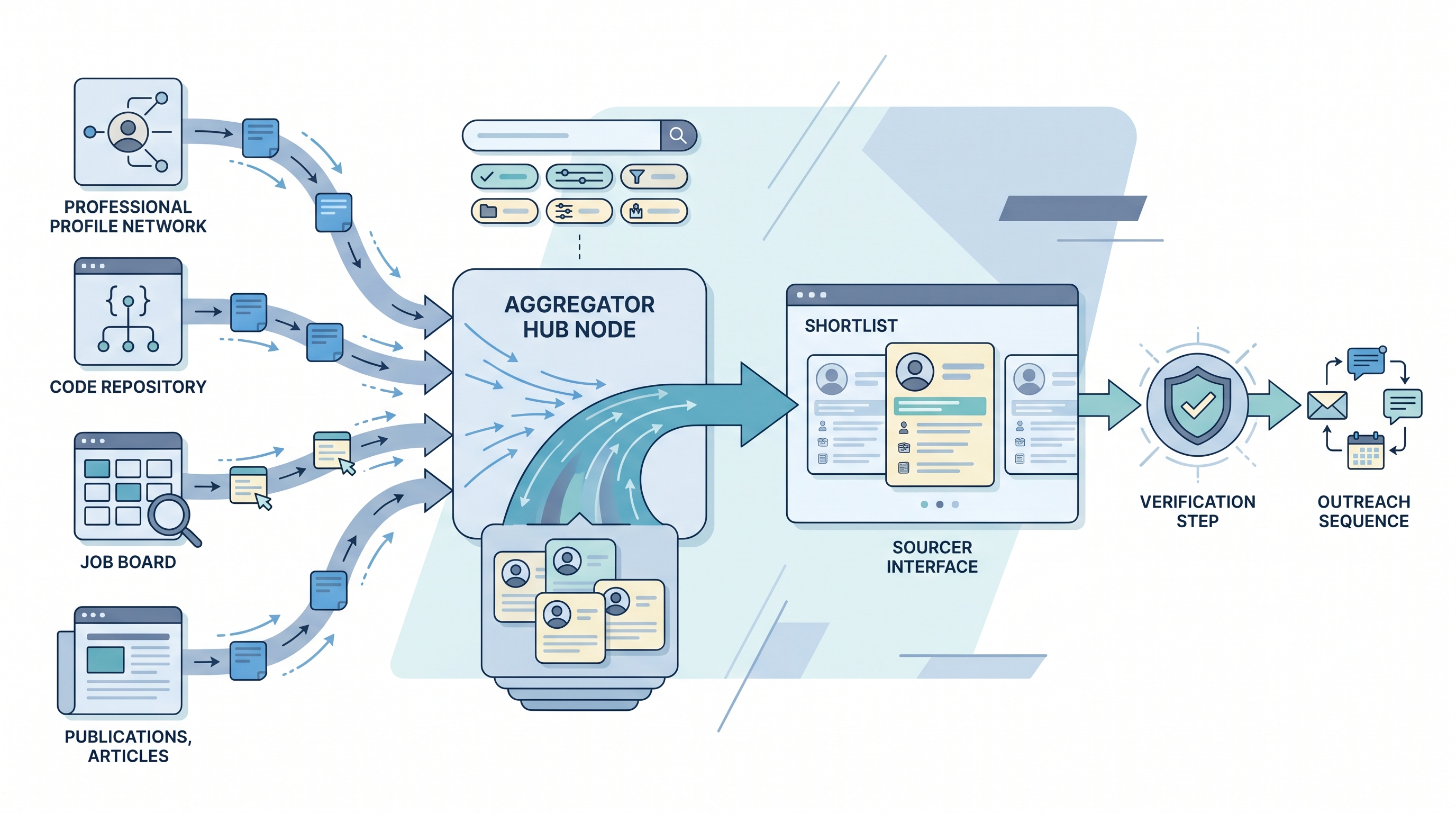
Talent data aggregators are platforms and APIs that compile candidate profile information from multiple public and licensed sources into a unified, searchable layer. Instead of a sourcer manually researching LinkedIn, GitHub, conference speaker lists, and professional publications for each candidate, an aggregator pre-compiles those signals into a single record so the discovery step is faster and the coverage is broader.
The output is a profile with fields already parsed: employer, title, skills, location, and sometimes a contact detail. What it is not is a verified, current record. Freshness and accuracy vary significantly by vendor and by persona, which is why aggregated data almost always needs a separate enrichment and verification step before an outreach sequence runs.
In practice
- A sourcer building a pipeline for a senior cloud security specialty queries an aggregator API with skills and title filters, gets 300 matching profiles back in seconds, and exports the top 80 to an enrichment tool for verified email addresses before loading them into a sequence. Without the aggregator, the same 80 profiles would take two days of manual research.
- A TA ops lead saying "our aggregator coverage is weak for this market" means the vendor has fewer than 100 records for the target persona in that geography, which pushes the team back to manual sourcing for that specialty regardless of the contract value.
- When legal asks "where did you get this candidate's contact details?" and the answer is "the platform," that is a documentation gap. The correct answer names the aggregator, its lawful basis, and when the record was last verified, because that chain is what a data subject access request requires.
Quick read, then how hiring teams use it
This is for recruiters, sourcers, TA, and HR partners who need the same vocabulary in debriefs, vendor calls, and policy reviews. Skim the first section when you need a fast shared picture. Use the second when you are deciding how it shows up in the ATS, sourcing tools, or candidate communications.
Plain-language summary
- What it means for you: Instead of visiting five websites to build one candidate profile, an aggregator pre-compiles those signals so your sourcing string returns a usable list rather than a research project.
- How you would use it: Define your criteria, query the aggregator UI or API, export a shortlist, verify contact details, then load into your outreach sequence. Cross-check ten records against direct sources before trusting the vendor's accuracy claim.
- How to get started: Pick one aggregator, define your target persona, pull 50 profiles, and check freshness against LinkedIn directly. If current employer accuracy is above 75 percent for your persona, proceed to a pilot campaign.
- When it is a good time: When manual sourcing for the specialty takes more than 30 minutes per profile and the candidate universe is large enough that speed beats relationship depth.
When you are running live reqs and tools
- What it means for you: Every aggregator in your sourcing stack is a subprocessor that needs a signed DPA, a named lawful basis, and a retention schedule. The speed benefit disappears if a data breach or access request exposes a gap in that documentation.
- When it is a good time: After legal has signed off on the vendor DPA, the CRM has a source field per record, and there is a named owner for the enrichment and verification step that sits between aggregator output and sequence import.
- How to use it: Layer aggregator data under a verification tool. Log source, pull date, and verification outcome per record. Build a deletion schedule for records that do not convert to active pipeline within your DPA retention window.
- How to get started: Benchmark your top two candidate personas against two or three vendor APIs before choosing. Ask each vendor for coverage numbers in your specific geography and specialty, not aggregate platform statistics.
- What to watch for: Static datasets sold as live data, vendors that do not offer EU data residency for GDPR-sensitive markets, skills data parsed from text rather than verified competencies, and integration gaps that require manual export-import between the aggregator and your CRM.
Where we talk about this
On AI with Michal live sessions, sourcing automation blocks treat talent data aggregators as the first node in a multi-step pipeline: query, enrich, verify, sequence. The session covers how to evaluate coverage, wire DPAs, and log the chain for compliance. If you want to map your vendor stack against peers running real pipelines, join Sourcing Lab and bring a sample of your current sourcing output.
Around the web (opinions and rabbit holes)
Third-party creators move fast here. Treat these as starting points, not endorsements, and verify GDPR posture and data residency directly before wiring candidate data.
YouTube
- People Data Labs API walkthrough covers the API-first enrichment pattern that feeds most enterprise sourcing automation stacks.
- Clay tutorial: building a multi-source talent pipeline walks waterfall enrichment logic that connects multiple aggregators in a single flow.
- How Apollo works for recruiting covers the combined search and outreach layer that sits on top of their aggregated profile data.
- Best talent data providers for recruiting? in r/sourcing compares vendor accuracy with blunt real-world numbers from people running live campaigns.
- Anyone using People Data Labs or Clearbit for sourcing? in r/recruiting is a frank thread on hit rates, GDPR compliance, and where the data actually comes from.
- GDPR and third-party candidate data: what do you actually do? in r/Recruitment covers the compliance angle that vendor sales decks skip.
Quora
- What are the best sources for passive candidate data? collects practitioner answers on aggregators, manual sourcing, and when each approach is the right choice.
Aggregator versus sourcing platform
| Layer | What it provides | When you need it |
|---|---|---|
| Talent data aggregator | Raw compiled profiles from multiple sources | Discovery and enrichment at scale |
| Sourcing platform | Workflow: search, sequence, CRM, ATS sync | End-to-end sourcing operations |
| Verification tool | Confirms contact details are live | Before sequence import |
| Your CRM | Owns the candidate record long-term | After pipeline is built |
Related on this site
- Glossary: Contact enrichment for sourcing, Candidate data enrichment, Multi-channel talent sourcing, Outbound talent sourcing, Workflow automation, GDPR and first-touch outreach
- Blog: AI sourcing tools for recruiters
- Guides: Sourcers
- Live cohort: Sourcing Lab
- Membership: Become a member