Async assessment platform
Software that lets candidates complete skills tests, video responses, or work samples on their own schedule, then stores structured results for reviewers to evaluate without a live scheduling dependency.
Michal Juhas · Last reviewed May 15, 2026
What is an async assessment platform?
An async assessment platform lets candidates complete evaluated tasks on their own schedule rather than on a live call. The candidate logs in at a time that suits them, submits a work sample, records a video response, or takes a skills test, and the platform stores the structured output for a reviewer to evaluate later.
The key feature is time-decoupling: the candidate does not need to be available when the reviewer is available, and the reviewer does not need to be available when the candidate submits. That asymmetry removes scheduling as a bottleneck in high-volume pipelines and lets teams evaluate more candidates without adding more live screening capacity.
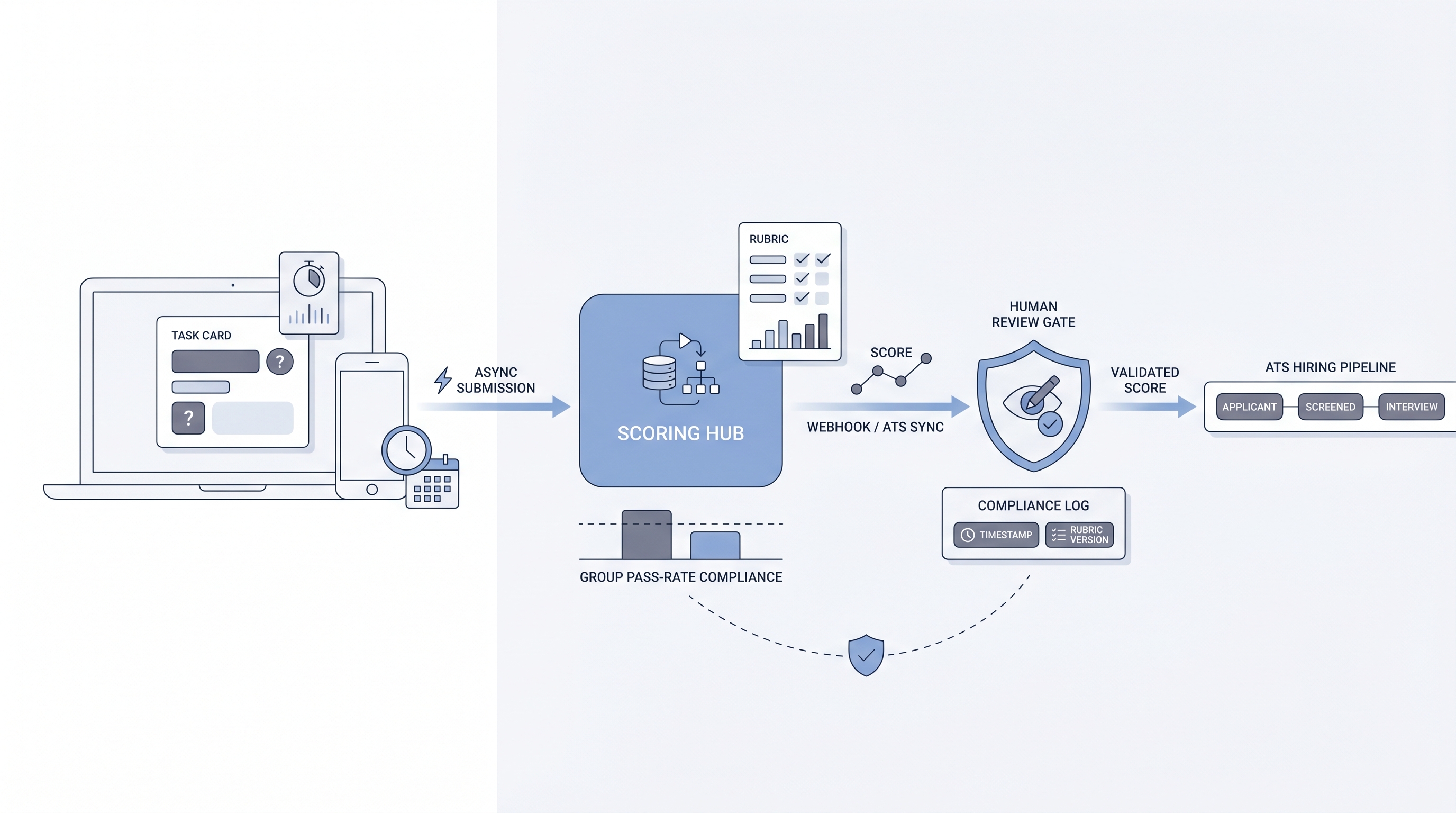
In practice
- When a high-volume customer support team sends a written scenario response to every applicant before the phone screen, and a TA coordinator reviews the results in a batch each morning, that is an async assessment platform workflow. The coordinator is not scheduling calls with 80 candidates; they are reviewing 80 structured submissions.
- Phrases like "take-home assignment," "skills test," and "async video screen" all refer to variations of the same idea, though they imply different formats. The platform that hosts and scores them is the async assessment platform.
- TA ops teams that report lower time-to-first-decision on senior engineering roles often point to moving a work sample before the hiring manager screen as the change, because the manager spends the live call on the output rather than probing for baseline skill.
Quick read, then how hiring teams use it
This is for recruiters, sourcers, TA, and HR partners who need the same vocabulary in debriefs, vendor calls, and policy reviews. Skim the first section when you need a fast shared picture. Use the second when you are deciding how async assessment fits into your stack, your compliance obligations, or your candidate experience.
Plain-language summary
- What it means for you: Instead of scheduling a call to ask someone if they can do the job, you send them a task and review what they actually produced. The review happens on your timeline, not theirs.
- How you would use it: You pick a task that tests a skill the role requires, you write a rubric before sending it, and you review every submission against the same criteria. The platform stores the result and pushes it to your ATS.
- How to get started: Identify one screening question your team asks the same way on every phone screen. Write it as a scored task with a three-point rubric. Pilot it with five candidates on your next open req and compare the output to your current phone screen notes.
- When it is a good time: When you are screening more candidates than your team can schedule calls with, when the role has a clear and testable skill, and when your process is stable enough that the rubric will not change mid-search.
When you are running live reqs and tools
- What it means for you: Every scored output is data that can be audited, compared across groups, and questioned by a candidate who receives a rejection. That is a governance asset when the rubric is documented and a liability when it is not.
- When it is a good time: After the scoring rubric is written, reviewed by the hiring manager, and tested internally. Not before. Sending an assessment without a rubric is scoring based on vibes, which undermines the main reason to use the platform.
- How to use it: Wire the platform to your ATS so scores land in the candidate record without manual entry. Configure the ATS stage to require human review before auto-advance. Log the rubric version, the reviewer, and the submission date alongside the score. Cross-link to workflow automation once the data mapping is trusted.
- How to get started: Run a group pass-rate check on the first 50 completions. If one protected group is passing at less than 80 percent of the rate of the highest-passing group, investigate the rubric before scaling. This is the four-fifths rule used in adverse impact monitoring.
- What to watch for: Completion rates below 60 percent often signal that the task length, instructions, or perceived relevance is driving qualified candidates out before you see their work. AI scoring that operates as a black box without a human review gate before stage decisions is a compliance risk in most jurisdictions. Rubric drift, where reviewers stop using the rubric and revert to gut feel after the first week, makes the assessment data unreliable for comparisons across batches.
Where we talk about this
On AI with Michal live sessions, async assessments come up in two places: the AI in recruiting track covers how to write a rubric that survives reviewer calibration and how to wire assessment data to ATS stage logic without creating silent failures. The sourcing automation track covers the integration side: webhooks, score field mapping, and dead-letter handling when a submission arrives but the payload does not write correctly. If you want the room conversation with other practitioners running real pipelines, start at Sourcing Lab and bring your current assessment setup and your ATS field mapping.
Around the web (opinions and rabbit holes)
Third-party creators move fast. Treat these as starting points, not endorsements, and double-check anything before you wire candidate data.
YouTube
- How to Create a Skills Assessment for Recruiting covers the basics of building a rubric and piloting assessments before scaling, useful for teams starting from scratch.
- Async Video Interviews vs. Traditional Phone Screens compares the candidate experience and reviewer calibration challenges of one-way video responses versus phone-based screening.
- Pre-Employment Testing Best Practices covers validity, adverse impact, and legal compliance basics for skills assessments in a hiring context.
- Anyone using async assessments instead of phone screens? in r/recruiting collects honest practitioner takes on completion rates, candidate experience, and when the format actually saves time.
- Best practices for take-home assignments? in r/ExperiencedDevs is written from the candidate side and is useful for understanding where async assessments lose trust with technical candidates.
- Thoughts on using HireVue or similar? in r/humanresources has a range of HR and TA perspectives on AI scoring platforms.
Quora
- What are the pros and cons of using pre-employment assessments in hiring? collects practitioner and candidate views on when assessments add signal versus create friction.
Async assessment versus live skills interview
| Dimension | Async assessment | Live skills interview |
|---|---|---|
| Scheduling dependency | None for candidate | Requires calendar alignment |
| Rubric requirement | Mandatory before launch | Beneficial but often skipped |
| Reviewer throughput | Batch review possible | One-to-one time commitment |
| Candidate experience signal | Completion rate is visible | Drop-off is invisible |
| Adverse impact monitoring | Straightforward from stored scores | Requires structured note system |
| AI scoring feasibility | High for structured outputs | Low for conversational nuance |
Related on this site
- Glossary: Async screening, One-way video interview, Scorecard, Adverse impact, AI bias audit, ATS API integration, Workflow automation, Human-in-the-loop (HITL), Candidate assessment tools
- Blog: AI sourcing tools for recruiters
- Guides: Sourcers
- Live cohort: Sourcing Lab
- Self-paced: Starting with AI: the foundations in recruiting
- Membership: Become a member