Scorecard
A structured rubric (traits, levels, evidence prompts) that tells recruiters and hiring managers what "good" looks like before interviews, so screening stays consistent and model-assisted drafts have something true to rest on.
Michal Juhas · Last reviewed May 2, 2026
What is a scorecard?
A scorecard is a simple grid that says what "good" looks like for a role before interviews start. Recruiters and hiring managers score against the same traits and examples so feedback stays fair and comparable.
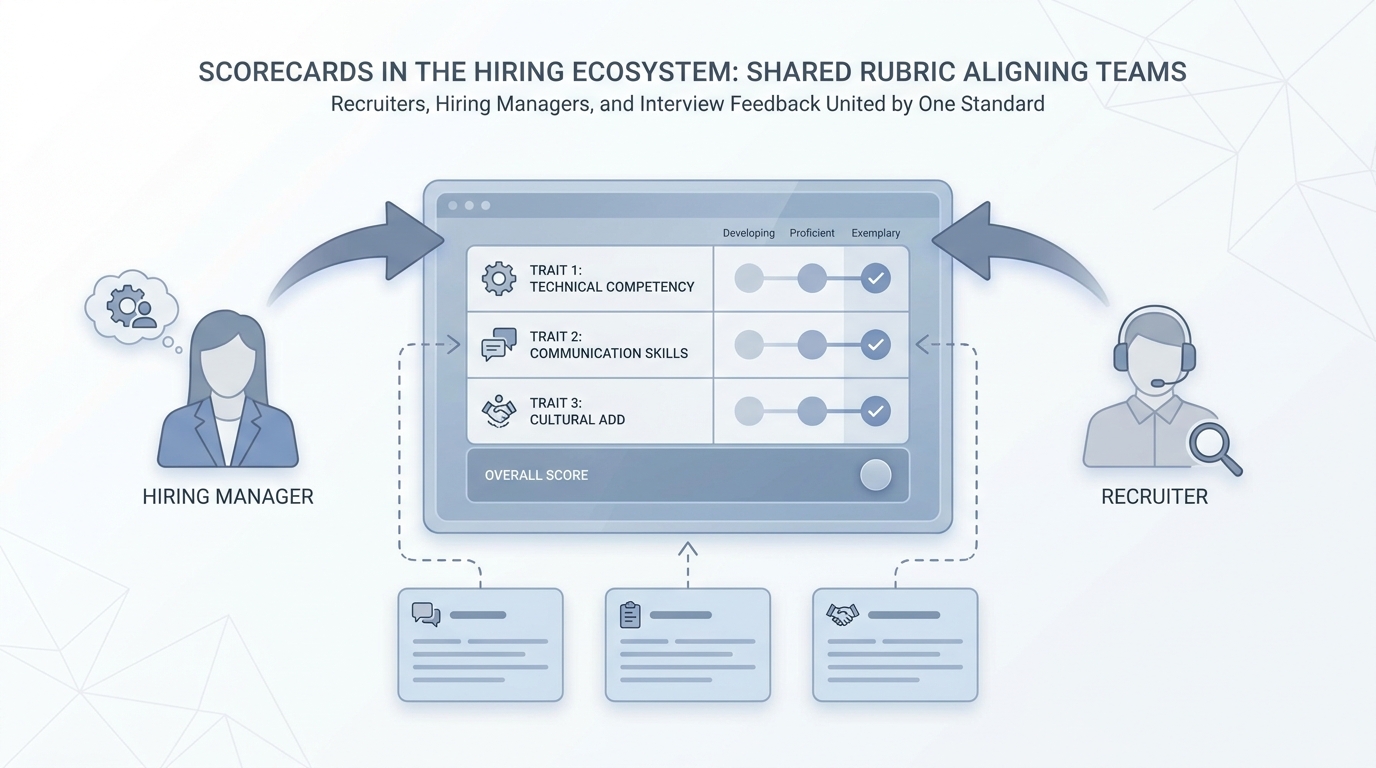
In practice
- Hiring managers see a one-page grid labeled "what strong looks like" before interviews on a senior hire. Training courses called it a scorecard or rubric long before AI tools showed up.
- After debriefs, two recruiters compare notes using the same trait names, which cuts "we felt different things" fights. People say "let's align on the scorecard" in calibration meetings.
- When someone asks ChatGPT to score a resume, the traits should already live in a doc the team agreed on. Otherwise the numbers look official but mean nothing in the room.
Quick read, then how hiring teams use it
This is for recruiters, sourcers, TA, and HR partners who need the same vocabulary in debriefs, vendor calls, and policy reviews. Skim the first section when you need a fast shared picture. Use the second when you are deciding how it shows up in the ATS, sourcing tools, or candidate communications.
Plain-language summary
- What it means for you: A scorecard is the same short list of criteria every interviewer marks so debriefs compare apples to apples.
- How you would use it: You read the job, you pick five behaviors that matter, you stick to them in every loop.
- How to get started: Steal one scorecard from a hiring manager who already believes, pilot on the next three candidates.
- When it is a good time: When debriefs are "I liked them" versus "I did not vibe" and leadership wants fairness language.
When you are running live reqs and tools
- What it means for you: Scorecards are structured evidence: competencies, rating anchors, and behavioral examples. They pair with structured output when models draft pre-reads, not decisions.
- When it is a good time: When you connect AI-native practices to legally defensible processes.
- How to use it: Train interviewers on anchors, audit variance across panels, and forbid free-text-only notes for final decisions.
- How to get started: Read Greenhouse or internal enablement templates, then localize to your bar.
- What to watch for: Score inflation, duplicate criteria that correlate 1:1, and AI "scores" shipped without human calibration.
Where we talk about this
AI in recruiting sessions use scorecards as the bridge between model drafts and hiring-manager trust. If your rubric is messy, bring redacted examples to Sourcing Lab.
Around the web (opinions and rabbit holes)
Third-party creators move fast. Treat these as starting points, not endorsements, and double-check anything before you wire candidate data.
YouTube
- Introduction to Large Language Models (Google Cloud Tech) is not scorecard-only, but TA committees often watch it together before debating AI rubrics.
- The AI Adoption Curve Explained (IBM Technology) helps when scorecards sit inside a wider transformation story.
- One-Way Video Interviewing Explained | Asynchronous & On-Demand (Spark Hire) is vendor-colored async content; still useful when you compare structured steps across live versus async stages.
- Interview Scorecard: what are you using? in r/recruiting compares tools from spreadsheets to ATS modules.
- Candidate scorecards in r/RecruitmentAgencies discusses objective evaluation habits.
- Interview notes are a mess and killing debrief quality in r/recruiting argues for structured evidence.
Quora
- What is a scorecard in hiring? is general HR vocabulary (read critically).
Scorecard versus unstructured notes
| Artifact | Hiring signal quality | Model usability |
|---|---|---|
| Freeform notes | Variable | Low |
| Scorecard | Calibratable | High |
| Scorecard + examples | Highest teaching value | Best for few-shot |
Related on this site
- Blog: How to use AI in recruiting
- Tools: Gemini
- Guides: Sourcers
- Course: Starting with AI: the foundations in recruiting