Few-shot prompting
Giving a language model a small set of completed examples (input plus desired output) so it infers tone, format, and constraints instead of you describing them only with adjectives.
Michal Juhas · Last reviewed May 2, 2026
What is few-shot prompting?
Few-shot prompting means you show the AI a few finished examples, each with an input and the answer you want, before you ask for something new. The model copies the pattern, tone, and layout from those examples instead of guessing from a long rule list.
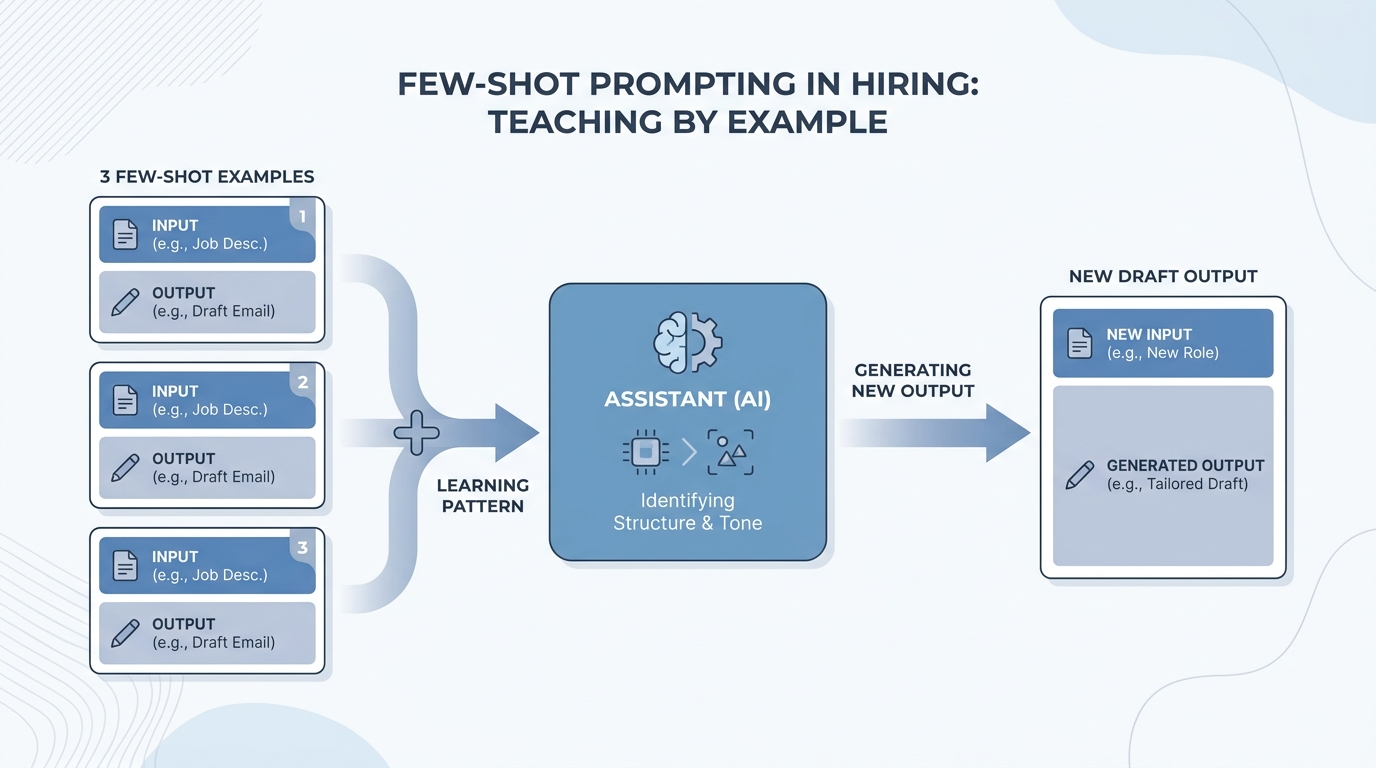
In practice
- Before you ask for twenty outreach variants, you paste three real messages your team already sent that got replies. Trainers often say "show it a few good examples first" instead of using the term few-shot.
- When you onboard a new recruiter, you share a doc with a bad email and a good email and tell them to drop those at the top of each ChatGPT or Claude session. That is the same habit with a simple file, not a lab notebook.
- For job ad rewrites, you might paste one paragraph you like and one you hate so the model can see the tone gap in plain sight. Hiring managers recognize that flow even if they never name the technique.
Quick read, then how hiring teams use it
This is for recruiters, sourcers, TA, and HR partners who need the same vocabulary in debriefs, vendor calls, and policy reviews. Skim the first section when you need a fast shared picture. Use the second when you are deciding how it shows up in the ATS, sourcing tools, or candidate communications.
Plain-language summary
- What it means for you: You show the AI two or three short examples of "good" output before you ask for a new one, like showing a new hire an old ticket.
- How you would use it: You paste anonymized samples with the tone you want, then you ask for the next version in that style.
- How to get started: Save one great intake note and one bad one. Label them. Ask the model to rewrite a third case like the great one.
- When it is a good time: When long instructions did not work and the format still drifts between recruiters.
When you are running live reqs and tools
- What it means for you: Few-shot is in-context learning: exemplars steer formatting and tone without fine-tuning. It competes with long prose rules and with system instructions for the same token budget.
- When it is a good time: When you need consistent bullets, score snippets, or outreach variants under one brand voice.
- How to use it: Rotate fresh examples, anonymize aggressively, and version the pack when comp or policy language changes.
- How to get started: Read How to write better AI prompts and build a three-example library for your highest-volume ask.
- What to watch for: Overfitting to three old reqs, leaking PII inside "good" examples, and stale shots nobody updates.
Where we talk about this
Live sessions compare few-shot packs to Gems and skills: same idea, different packaging. AI in recruiting focuses on tone and fairness; sourcing automation focuses on stable fields feeding prompts. Try both angles at Sourcing Lab.
Around the web (opinions and rabbit holes)
Third-party creators move fast. Treat these as starting points, not endorsements, and double-check anything before you wire candidate data.
YouTube
- Let's build GPT: from scratch, in code, spelled out (Andrej Karpathy) explains why examples in context change behavior.
- Introduction to Large Language Models (Google Cloud Tech) covers prompting vocabulary leaders repeat.
- But what is a GPT? Visual intro to transformers (3Blue1Brown) is optional depth when your team asks how examples change behavior.
- Few shot examples vs long prompt? in r/ChatGPT debates where each style wins.
- How is AI being used in your recruiting process? in r/recruiting includes informal few-shot habits people do not name as such.
- How do you chain multiple LLM calls? in r/LangChain is builder-heavy but shows how examples stack in real pipelines.
Quora
- What is few-shot learning in machine learning? is textbook-framed; translate to prompting, not training jobs.
Few-shot versus long instructions
| Style | When it wins | Watch out |
|---|---|---|
| Few-shot | Tone, format, micro-patterns | Hidden bias in samples |
| Long rubric | Legal must-nots, compliance | Token cost, skim risk |
| Hybrid | Production prompts | Needs an owner to edit both |
Related on this site
- Blog: How to use AI in recruiting
- Tools: Gemini
- Guides: Recruiters
- Membership: Become a member