LLM tokens
The chunks of text models bill and reason over; context windows cap how much instruction, job description, and candidate material fit in one call, which shapes how recruiters package prompts and attachments.
Michal Juhas · Last reviewed May 2, 2026
What are LLM tokens?
A token is a small chunk of text the model reads and bills against, often part of a word or a punctuation mark. Long resumes and huge pastes use more tokens, so short summaries help the model focus and can lower cost.
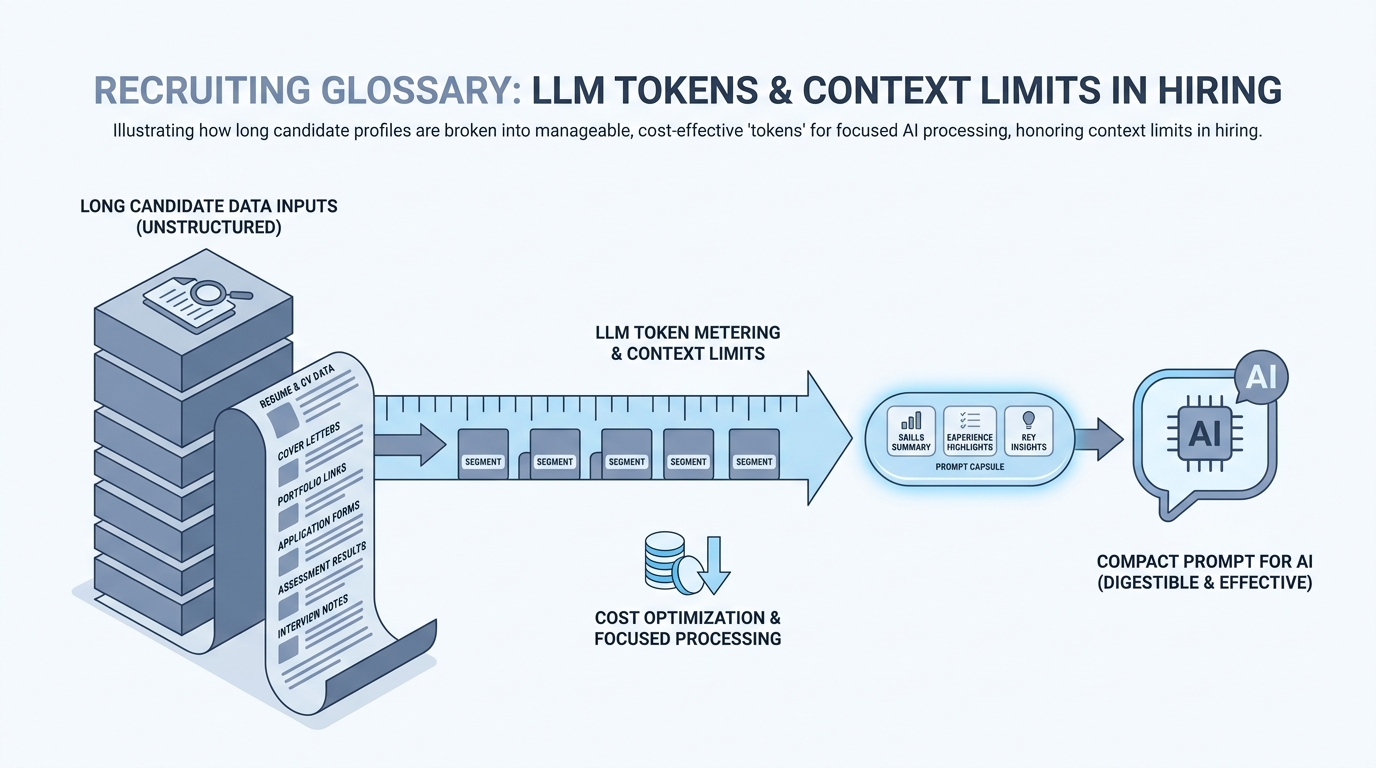
In practice
- On a ChatGPT invoice or admin screen you see "tokens used this month" next to dollar amounts. Finance forwards that email and asks recruiting "why did usage spike in Q3" when hiring was busy.
- Trainers warn "do not paste fifty resumes at once" because the app may cut off the bottom of the pile when it hits limits. The UI might only say "message too long," but the limit is counted in tokens.
- Partner sales decks compare cost "per thousand tokens" when pitching cheaper models to TA tech buyers who mostly care about monthly spend.
Quick read, then how hiring teams use it
This is for recruiters, sourcers, TA, and HR partners who need the same vocabulary in debriefs, vendor calls, and policy reviews. Skim the first section when you need a fast shared picture. Use the second when you are deciding how it shows up in the ATS, sourcing tools, or candidate communications.
Plain-language summary
- What it means for you: Tokens are how the computer counts text chunks for billing and for "how much fits in one box." Long pastes cost more and can get cut off at the bottom.
- How you would use it: You summarize before you paste, you delete old chat junk, and you attach only the pages that matter.
- How to get started: Take one twenty-page PDF, extract three paragraphs your sourcer actually reads, compare model behavior.
- When it is a good time: When finance forwards a usage spike email or when the UI says "message too long."
When you are running live reqs and tools
- What it means for you: Tokens meter prompts, tool outputs, and retrieval chunks against a context window. They drive cost, latency, and truncation risk alongside Markdown for AI hygiene.
- When it is a good time: When you wire workflow automation or bulk resume parsing.
- How to use it: Pre-compress with headings, tables, and excerpts; keep canonical sources outside the thread for audits.
- How to get started: Watch OpenAI's tokenizer demo, then set team norms on max paste sizes.
- What to watch for: Optimizing only for token count and stripping compliance-relevant detail, or assuming "bigger windows" fix hallucination risk.
Where we talk about this
Sourcing automation days talk about tokens when webhooks ship huge JSON blobs into models. AI in recruiting days talk about tokens when intake packs get obese. Bring your worst paste to Sourcing Lab.
Around the web (opinions and rabbit holes)
Third-party creators move fast. Treat these as starting points, not endorsements, and double-check anything before you wire candidate data.
YouTube
- Let's build the GPT Tokenizer (Andrej Karpathy) explains byte pair encoding the way engineers debug truncation.
- Introduction to Large Language Models (Google Cloud Tech) mentions context as a constraint, not magic memory.
- Let's build GPT: from scratch, in code, spelled out (Andrej Karpathy) helps technical partners understand embeddings and chunks.
- Few shot examples vs long prompt? in r/ChatGPT is also a token-budget conversation in disguise.
- Custom GPT knowledge limit in r/ChatGPT discusses file size versus usefulness.
- How do you organize your knowledge files? in r/OpenAI overlaps with keeping prompts lean.
Quora
- What are tokens in ChatGPT? is consumer-framed but maps to billing questions TA asks.
Rough mental model
| Input style | Typical outcome |
|---|---|
| Lean Markdown SOP | Predictable, cheap reruns |
| Full PDF dump | Noisy parse, higher cost |
| Chat thread archaeology | Important lines may truncate |
Related on this site
- Glossary: Markdown for AI, System instructions, Large language model
- Blog: How to use AI in recruiting
- Course: Starting with AI: the foundations in recruiting
- Membership: Become a member