Model evaluation for hiring
A structured process for testing an AI model's outputs against labelled hiring samples to measure accuracy, fairness, and consistency before deploying it in a live pipeline.
Michal Juhas · Last reviewed June 11, 2026
What is model evaluation for hiring?
Model evaluation for hiring is the structured process of testing what an AI model actually outputs before (and after) it touches live applications. You take a sample of real or synthetic profiles, run them through the model, compare the outputs to what trained humans decided, and look for gaps in accuracy, consistency, and group fairness.
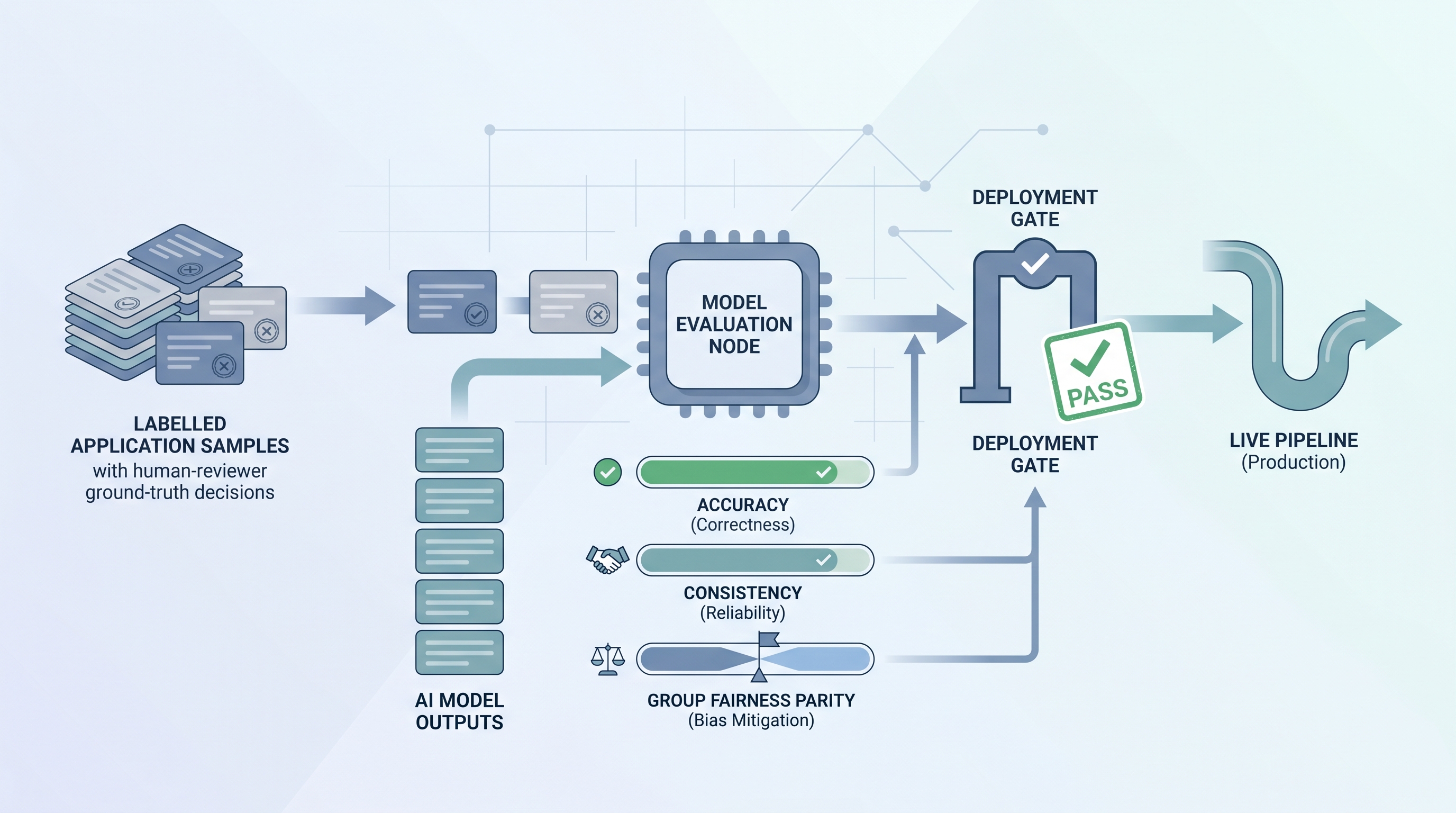
In practice
- A sourcing team runs 80 anonymised applications through a new screening tool, compares the model rankings to a recruiter panel that reviewed the same CVs blind, and flags three systematic mismatches before the tool goes live.
- A TA ops lead adds a "model version" tag to every ATS decision made by AI, then reruns a fairness check every quarter to see whether pass rates have drifted.
- A workshop participant says: "We thought the tool was working fine until we ran the same profile twice with different spacing and got different scores. That is when we built the evaluation checklist."
Quick read, then how hiring teams use it
This is for recruiters, TA ops, and HR tech leads who need to understand what they are actually deploying before it touches candidates. Skim the first section for shared vocabulary. Use the second for practical setup when you are buying or building an AI screening tool.
Plain-language summary
- What it means for you: Before any AI tool scores or ranks candidates in your pipeline, someone needs to check whether the outputs match what a fair human reviewer would decide, and whether some groups of candidates are systematically rated lower.
- How you would use it: Collect a labelled set of past applications, run them through the model, compare the outputs to your labels, and calculate how often the two agree and whether the gaps are even across candidate groups.
- How to get started: Pull 50 to 100 recent applications where you know the human outcome. Label them fresh without showing the model output to labellers first. Then run the model and compare.
- When it is a good time: Before deploying any new AI screening or ranking tool, after a model update from a vendor, and at least once a quarter for high-volume roles.
When you are running live reqs and tools
- What it means for you: Evaluation is your evidence layer. If a regulator, a candidate, or your legal team asks why a profile was rejected, your model evaluation log is the document that shows the system was checked before it ran.
- When it is a good time: After any major pipeline change: a new job family, an ATS migration, a prompt rewrite, or a model version bump. Treat each change as a new evaluation trigger.
- How to use it: Connect evaluation to your audit log. Tag every AI-assisted decision with the model version, the date, and the evaluation run that approved that version. If structured output feeds downstream automations, include the confidence score alongside the output.
- How to get started: Assign an owner (TA ops is a natural fit) and a cadence before the tool goes live. Document the accuracy threshold and the fairness threshold you agreed on, and record who signed off. Link to your AI bias audit process so they share the same labelled dataset.
- What to watch for: Model version updates from vendors that change underlying behaviour without announcement, seasonal shifts in applicant pools that drift fairness metrics, and overconfident outputs with no uncertainty signal attached.
Where we talk about this
In AI with Michal cohorts, model evaluation comes up in the AI in recruiting and sourcing automation tracks when teams try to move from pilots to production. The hard questions about ownership, labelling, and fairness thresholds get worked out in the room, not just in slides. If you want those conversations with your stack in front of you, the workshops page shows what is running next.
Around the web (opinions and rabbit holes)
Third-party resources move fast. Use these as starting points, not endorsements, and do not wire candidate data to any script you find without your security team reviewing it first.
YouTube
- Evaluating ML Models for Bias (Google for Developers) gives a technical walkthrough of fairness metrics that TA practitioners can adapt.
- How to Audit AI Systems (AI Now Institute) covers institutional accountability framing useful for HR tech conversations.
- r/MachineLearning: best practices for offline model evaluation has practitioner debates on held-out sets and leakage that carry over to hiring tool contexts.
- r/recruiting: has anyone evaluated an AI screening tool before buying? search surfaces several threads on vendor evaluation, though quality varies.
Quora
- How do companies evaluate AI hiring tools for fairness? collects answers from HR tech practitioners and legal professionals worth reading critically.
Related on this site
- Glossary: AI bias audit, Explainable AI in hiring, Human-in-the-loop (HITL), Structured output, Grounded outputs in hiring, EU AI Act in hiring
- Blog: AI sourcing tools for recruiters
- Workshops: AI in recruiting
- Membership: Become a member