Calibration session (hiring)
A structured meeting where a hiring panel agrees on scoring standards before or during an interview loop, ensuring every interviewer uses the same anchors when rating competencies rather than inventing a personal bar mid-search.
Michal Juhas · Last reviewed May 15, 2026
What is a calibration session in hiring?
A calibration session is a structured meeting where the hiring panel agrees on scoring standards before or during an interview loop. The goal is simple: every interviewer uses the same anchors when rating competencies, rather than each person inventing a personal bar mid-search.
Without calibration, a panel of four interviewers might all be using "strong communicator" to mean four different things. One person means they spoke clearly. Another means they structured their answer with a point, evidence, and takeaway. A third is weighting whether the candidate made eye contact. None of this surfaces in the debrief unless scores land far apart and someone asks why.
Calibration sessions usually involve a facilitator, a shared scorecard, and a sample transcript or past answer to score independently before any group discussion opens. The session ends with a written anchor document: what the panel agreed a 1, 3, and 5 look like for each competency, not in the abstract, but tied to the kind of evidence a candidate could actually give.
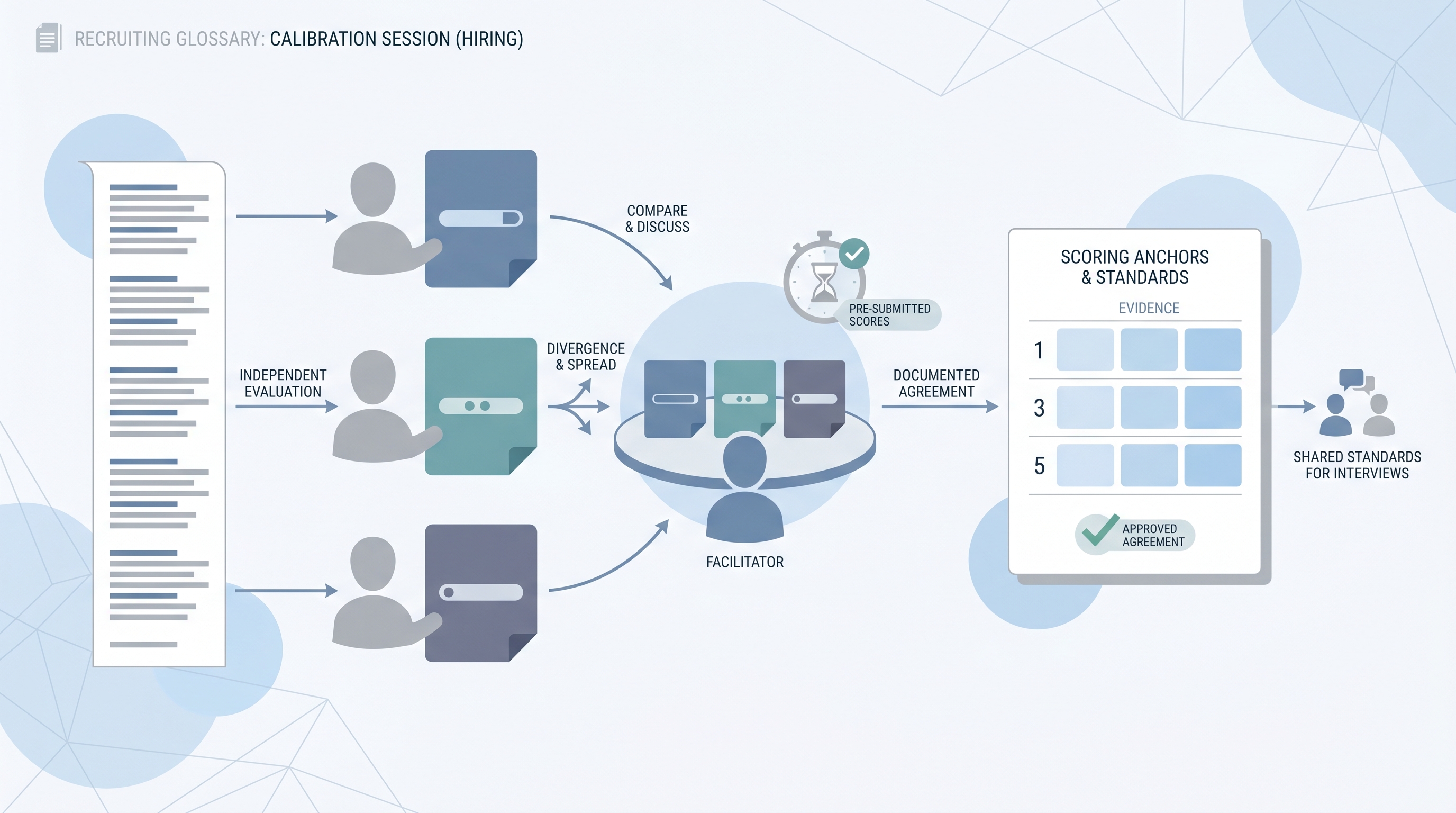
In practice
- When a recruiter says "the panel scored her a 2 and a 5 on the same competency for the same story," that is a calibration failure: two interviewers heard the same answer and used different rulers.
- A hiring manager who opens a debrief with "I thought she was great overall, what did everyone else think?" has already anchored the room before anyone shares their scorecard, which is exactly what calibration-led debriefs are designed to prevent.
- TA ops teams that run calibration before every new role report fewer debrief conflicts and faster hire-or-no-hire decisions because the panel is resolving evidence gaps, not redefining the criteria in real time.
Quick read, then how hiring teams use it
This is for recruiters, TA leads, and HR partners who need the same vocabulary in debrief calls, interview training, and process design. Skim the first section for a fast shared picture. Use the second when you are rolling out a new panel, onboarding a new interviewer, or investigating why debrief scores keep spreading.
Plain-language summary
- What it means for you: Before anyone interviews a candidate, the panel spends 30-60 minutes agreeing what a strong, average, and weak answer looks like for each competency. You write it down. You use the same document for every candidate.
- How you would use it: Run one calibration session per new role or per new panel composition, using a sample answer (past or synthetic) to score independently before the group compares. The gap between your scores is your agenda.
- How to get started: Pull the scorecard for your next active req. Write down what you personally think a 5 looks like for your most important competency. Send the same question to two other panelists before your next kickoff and compare answers. You will find the gap immediately.
- When it is a good time: Every time you open a new interview loop with a panel of two or more people. Single-interviewer screens benefit from calibration too, but the need is less acute.
When you are running live reqs and tools
- What it means for you: Calibration is the difference between scorecards that produce independent evidence and scorecards that become post-hoc rationalization of whoever spoke first in the debrief.
- When it is a good time: Before the first interview on a req, when a new panelist joins a running loop, and after any split decision where the debrief went longer than 20 minutes without resolution.
- How to use it: Designate a calibration facilitator (usually the recruiter or a debrief coordinator who attends every panel). Use a real or synthetic transcript, set a timer for independent scoring, compare spreads, and write the anchors down. Store the anchor document in the ATS or a shared folder the panel can reference during interviews.
- How to get started: Build a one-page anchor template into your standard interview package alongside the question set. Require it to be signed off before the first interview slot is booked, the same way you require the behavioral interview questions to be shared with the panel in advance.
- What to watch for: Panels that skip calibration when time is tight (the ones with 15 open reqs tend to skip it most), facilitators who open the group discussion before everyone has submitted independent scores, and anchor documents that get written once and never revisited when the req or panel changes. AI transcript tools can help diagnose drift post-hoc, but they do not replace the pre-interview alignment conversation.
Where we talk about this
On AI with Michal live sessions, calibration comes up whenever we connect structured scoring to debrief quality and ATS data reliability. In the AI in recruiting track, it sits alongside behavioral interview question design and scorecard setup as the three elements that determine whether your interview data is worth storing. If you want the full room conversation with other TA practitioners who are solving this in active hiring cycles, start at Sourcing Lab and bring a real scorecard you are working with.
Around the web (opinions and rabbit holes)
Third-party creators move fast. Treat these as starting points, not endorsements, and double-check anything before you wire candidate data to a new tool.
YouTube
- Structured Interviewing: Reducing Bias With Calibration (search) surfaces HR practitioner walkthroughs of pre-debrief calibration approaches and why inter-rater reliability matters.
- How to Run a Hiring Debrief That Actually Works (search) covers the mechanics of debrief facilitation, score submission order, and what to do when panelists disagree on the same evidence.
- Interview Calibration and Scorecard Anchors for TA Teams (search) shows the question-writing and anchor-setting workflows that cohort sessions build from the same principles.
- How do you actually run interview calibration at your company? in r/humanresources is a direct practitioner thread on what calibration looks like in real teams, from startups to enterprise.
- Our debrief always ends the same way: the HM just wins. How do you fix that? in r/recruiting covers the anchoring problem and what process changes actually help.
- Does your company actually use scorecards or is it just vibes? in r/humanresources is a frank discussion of the gap between documented processes and what panels actually do under time pressure.
Quora
- How do you calibrate interviewers so they all evaluate candidates the same way? collects perspectives from I-O psychologists, recruiting leaders, and HR practitioners on making calibration actually stick.
Calibration session vs. standard debrief
| Dimension | Calibration-led process | Standard debrief |
|---|---|---|
| Score submission timing | Before the meeting opens | During or after group discussion |
| Opening move | Facilitator shares spread anonymously | Senior person states overall impression |
| Anchor document | Written and signed before first interview | Implicit, improvised, or missing |
| Disagreement source | Evidence gaps vs. anchor gaps (separated) | Usually unclear |
| Bias exposure | Reduced (structure limits anchoring effect) | Higher (first speaker effect, seniority bias) |
| Documentation | Anchor record dated before evaluation | Typically absent |
Related on this site
- Glossary: Scorecard, Behavioral interview, Adverse impact, Human-in-the-loop (HITL), AI interview intelligence, Async assessment platform
- Blog: AI sourcing tools for recruiters
- Guides: Sourcers
- Live cohort: Sourcing Lab
- Self-paced: Starting with AI: the foundations in recruiting
- Membership: Become a member