Model guardrails
Rules or constraints that limit what an AI model can say or do in a hiring context, preventing outputs that are discriminatory, confidential, off-topic, or legally unsafe.
Michal Juhas · Last reviewed June 11, 2026
What are model guardrails?
Model guardrails are the constraints that define what an AI tool can say or do inside a hiring workflow. They combine written instructions, automated output filters, and human review gates to prevent outputs that are discriminatory, legally unsafe, off-brand, or simply wrong.
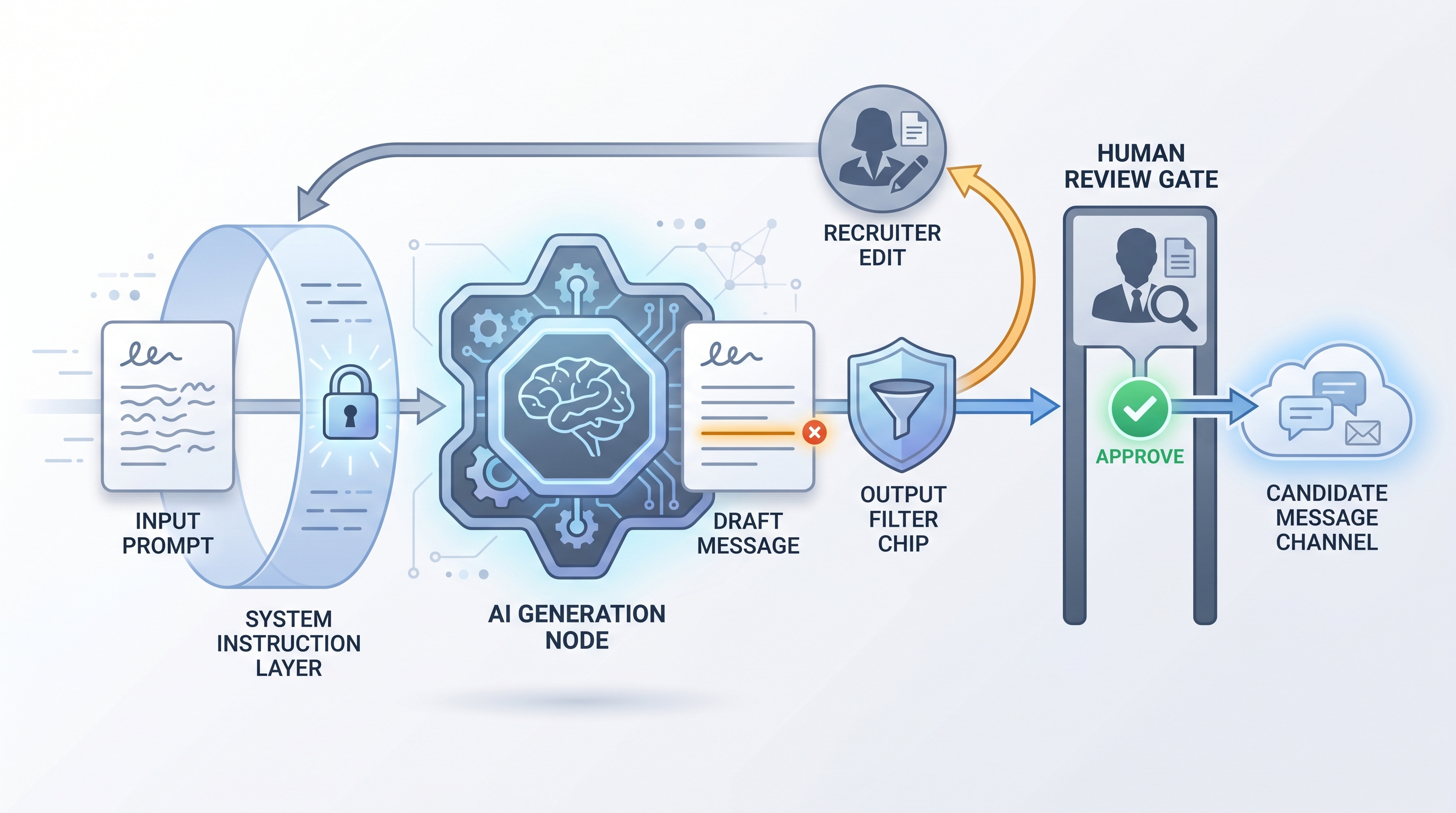
In practice
- A sourcing manager adds a system instruction that tells the outreach assistant to never ask about family status, visa status, or religion, then tests it with adversarial prompts before going live.
- A TA ops team routes any model output with a confidence score below a threshold into a human review queue rather than sending it directly, catching hallucinated company names and inflated salary ranges before candidates see them.
- In a workshop debrief, a recruiter describes discovering the model would promise interview timelines it could not guarantee until a guardrail blocked that category of statement and routed those questions to a human.
Quick read, then how hiring teams use it
This page is for recruiters, TA leaders, and HR tech partners who are deploying AI tools and need to understand what keeps those tools from creating legal, brand, or candidate-experience problems. Skim the first section for shared vocabulary. Use the second for practical implementation.
Plain-language summary
- What it means for you: Guardrails are the rules that stop an AI tool from saying something you cannot take back, like implying a preference for younger candidates or promising a start date that is not confirmed.
- How you would use it: Write down what the model must never say (protected characteristics, compensation promises), what it should always include (legal disclaimers, next-step routing), and who reviews borderline outputs before they reach candidates.
- How to get started: Start with your most common candidate-facing use case (outreach, FAQ answers, or screening questions), list five things the model should never say for that use case, and turn those into system instructions you can test.
- When it is a good time: Before any candidate-facing deployment and before expanding an internal tool to new use cases where the risks differ.
When you are running live reqs and tools
- What it means for you: Guardrails are your audit trail. If a regulatory body or a candidate asks why a message said what it said, your guardrail documentation shows the constraints that were active at the time.
- When it is a good time: Whenever you update the model, change a system instruction, or add a new use case. Treat each change as a new deployment requiring a guardrail review.
- How to use it: Layer the controls. Pre-generation: system instructions define scope and tone. Post-generation: output filters check for prohibited terms or formats. Human gate: route low-confidence or edge-case outputs to a recruiter before they leave the system.
- How to get started: Review one week of model outputs, identify the top five categories of output you are uncertain about, and assign a guardrail to each. Document the version of each instruction and who approved it.
- What to watch for: Model version updates from vendors that change underlying behaviour without notice, prompt-crafting that bypasses system instructions, and refusal rates that indicate over-constraining. All three appear in sourcing automation sessions when teams move from pilots to production.
Where we talk about this
In AI with Michal cohorts, guardrail design comes up in every sourcing automation and AI in recruiting block because teams consistently discover the model will say something they did not anticipate. The room conversation about what to lock down, what to leave flexible, and who owns the review queue is more useful than any template. Check workshops for upcoming sessions and bring your actual system instructions for live review.
Around the web (opinions and rabbit holes)
Starting points only. Double-check anything before wiring it to candidate communications.
YouTube
- Prompt Injection Attacks: What They Are and How to Defend (Simon Willison) covers the guardrail-bypassing attack mode that HR tech teams underestimate.
- Building Safe AI Systems (Anthropic) explains the principles behind model-level safety that inform vendor guardrail claims.
- r/LanguageTechnology: best practices for LLM output filtering has practitioner threads on post-generation filter implementation.
- r/recruiting: AI tools refusing to answer basic questions search surfaces recruiter frustrations with over-constrained tools, useful for calibration.
Quora
- How do HR teams prevent AI tools from saying discriminatory things? collects practitioner and legal answers worth reading before you finalise your instruction set.
Related on this site
- Glossary: System instructions, Human-in-the-loop (HITL), Hallucination, RAG, AI bias audit, EU AI Act in hiring
- Workshops: AI in recruiting
- Membership: Become a member