Outreach personalization at scale
Using structured data fields, prompt templates, and AI generation to write recruiting outreach that reads as personally relevant to each recipient while being produced faster than one message at a time.
Michal Juhas · Last reviewed June 11, 2026
What is outreach personalization at scale?
Outreach personalization at scale means writing recruiting messages that feel relevant to each individual candidate while producing them at a volume and speed that manual writing cannot match. The tools are AI generation and prompt templates; the requirement that makes it work is accurate data, calibrated prompts, and a human read before each send.
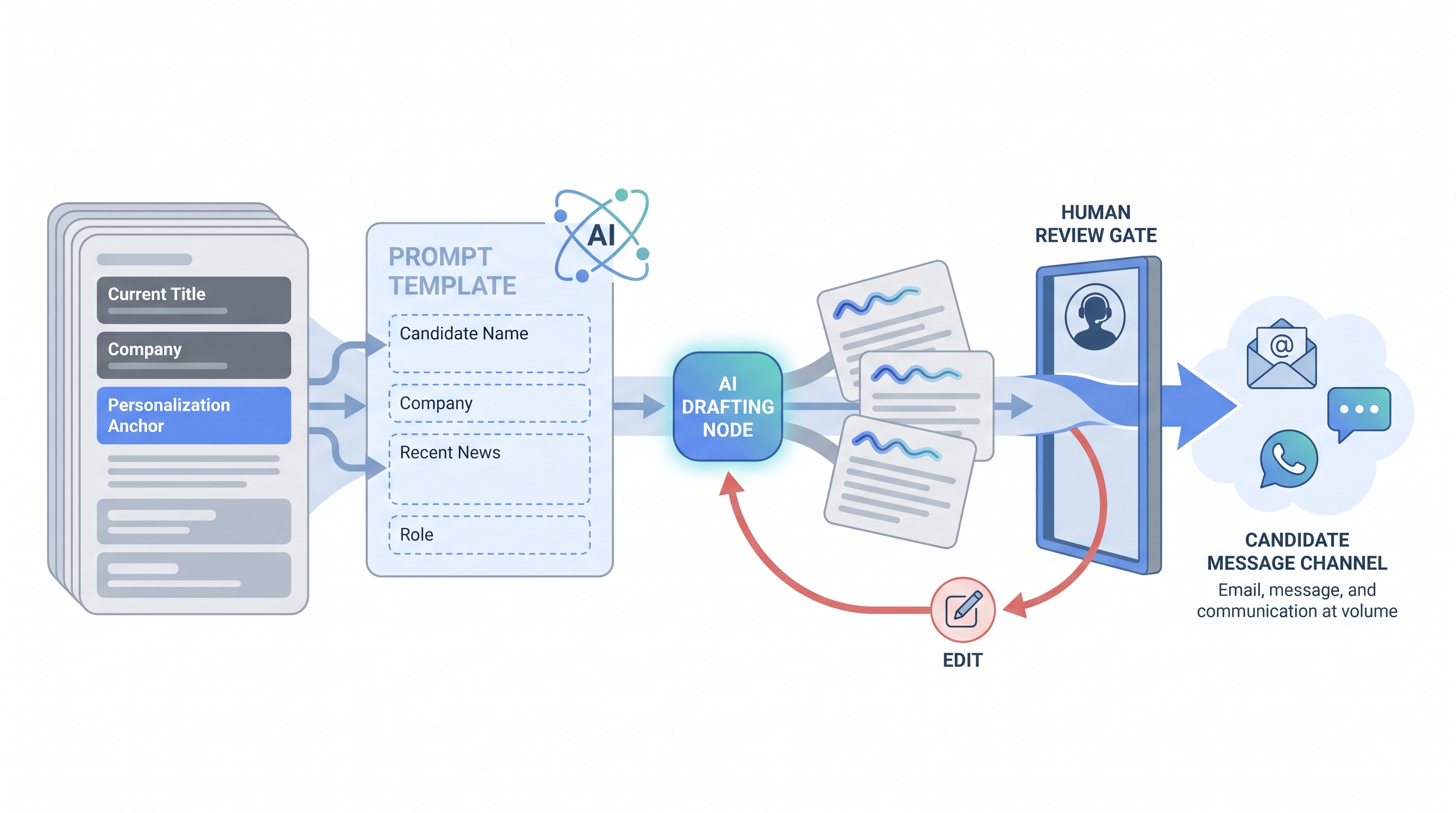
In practice
- A sourcer builds a prompt that takes three fields from each profile (current title, most recent company, one specific project listed) and produces a three-sentence opening message tailored to each person. She reviews 20 outputs before enabling the flow and catches two hallucinated project references and one message that was too long.
- A TA team tests two message variants for a data engineering role over 200 sends: one with a personalised second sentence referencing the candidate's open-source contribution and one without. Reply rate is 22% versus 9%.
- A workshop participant describes stopping a personalisation workflow after realising the enrichment tool was inferring graduation year from profile data, which was being fed into the prompt and accidentally correlating age with message style. Auditing data sources before they enter prompts is now a step in their playbook.
Quick read, then how hiring teams use it
This is for sourcers, recruiters, and TA ops partners who want to improve outreach reply rates using AI without creating compliance exposure or publishing messages that read as automated. Skim for shared vocabulary, then use the second section for practical setup.
Plain-language summary
- What it means for you: Personalisation at scale is the difference between a template with a first name token and a message that opens with something specific enough that the candidate knows you actually looked at their work.
- How you would use it: Build a prompt template that takes verified fields from each profile, generates a personalised opening paragraph, and routes the output through a human review before sending.
- How to get started: Take your best-performing current outreach message, identify the two most generic sentences, and replace them with a field that your sourcing tool can pull from each profile. That one change is the first iteration.
- When it is a good time: For roles where the target population is large enough to justify prompt iteration (100 or more profiles) and specific enough that a personalised detail is meaningful.
When you are running live reqs and tools
- What it means for you: At volume, even small improvements in reply rate compound: a 10-percentage-point lift on 500 sends is 50 additional conversations. The investment in building a clean template and a review step pays back faster than it looks from the setup cost.
- When it is a good time: After you have a stable target profile (ICP defined, sourcing filters set), before you scale the send volume. Iterating the prompt on 50 sends before 500 prevents an 8% reply-rate campaign from becoming a buried data point.
- How to use it: Ground prompts on verified data only. Use few-shot prompting with two or three example messages that match your tone. Instruct the model not to infer or elaborate beyond the provided fields. Read five outputs before any batch send.
- How to get started: Audit the data fields in your current outreach workflow. List every field that enters a prompt and confirm its source and accuracy rate. Remove any field enriched from a source you cannot verify. Then build the template.
- What to watch for: Hallucinated profile details (the model invents a project not in the source data), inferred demographic proxies in enriched fields, opt-out handling lag when scale increases, and reply-rate drift that signals the template needs a refresh.
Where we talk about this
In AI with Michal cohorts, outreach personalisation is one of the first hands-on exercises in sourcing automation blocks because the gap between "AI wrote this" and "a human actually looked at my profile" is something participants feel immediately when they read each other's outputs. The prompt review step, the data quality check, and the GDPR conversation all come out of working through real examples in the room. See workshops for upcoming sessions, and bring a real campaign you are running.
Around the web (opinions and rabbit holes)
Starting points only. Test any framework against your own reply-rate data before scaling.
YouTube
- How to Write Personalized Recruiting Messages with AI (Beamery) covers prompt-based personalisation with a practical walkthrough.
- The Science of Recruiter Outreach Reply Rates (Talent Innovation) presents A/B test data on what message elements actually lift replies.
- r/recruiting: what makes a cold outreach message actually get a reply? has hundreds of practitioner answers including negative examples.
- r/linkedin: recruiters please stop sending these messages gives the candidate perspective on what reads as automated and what does not.
Quora
- How do recruiters personalise outreach to passive candidates at scale? surfaces a range of practitioner and sourcer answers worth reading before you build your first template.
Related on this site
- Glossary: Few-shot prompting, Candidate data enrichment, GDPR first-touch outreach, AI outreach drafting, Adverse impact, Prompt chain
- Blog: AI sourcing tools for recruiters
- Workshops: AI in recruiting
- Membership: Become a member