Fine-tuning for domain models
Fine-tuning for domain models means taking a general-purpose language model and training it further on a narrow corpus (your outreach, intake notes, classification labels) so the model bakes in your tone, taxonomy, and judgment instead of relying on prompts every call.
Michal Juhas · Last reviewed May 27, 2026
What is fine-tuning for domain models?
Fine-tuning for domain models is the heavy lift of AI customization: you take a general-purpose language model and train it further on a curated set of your own examples so the model internalises your tone, taxonomy, and judgment without you re-explaining the rules in every prompt. For a recruiting team that already runs solid system instructions, few-shot prompting, and RAG, fine-tuning is the next step only when the same task repeats often enough that pinning the weights pays for the labeling, the evals, and the retrains.
Most TA teams will get further with better prompts and retrieval than with a fine-tune. The right test is not "could we", it is "does this pattern repeat enough that prompting has stopped scaling, and is the output shape stable enough that we will not retrain every month?"
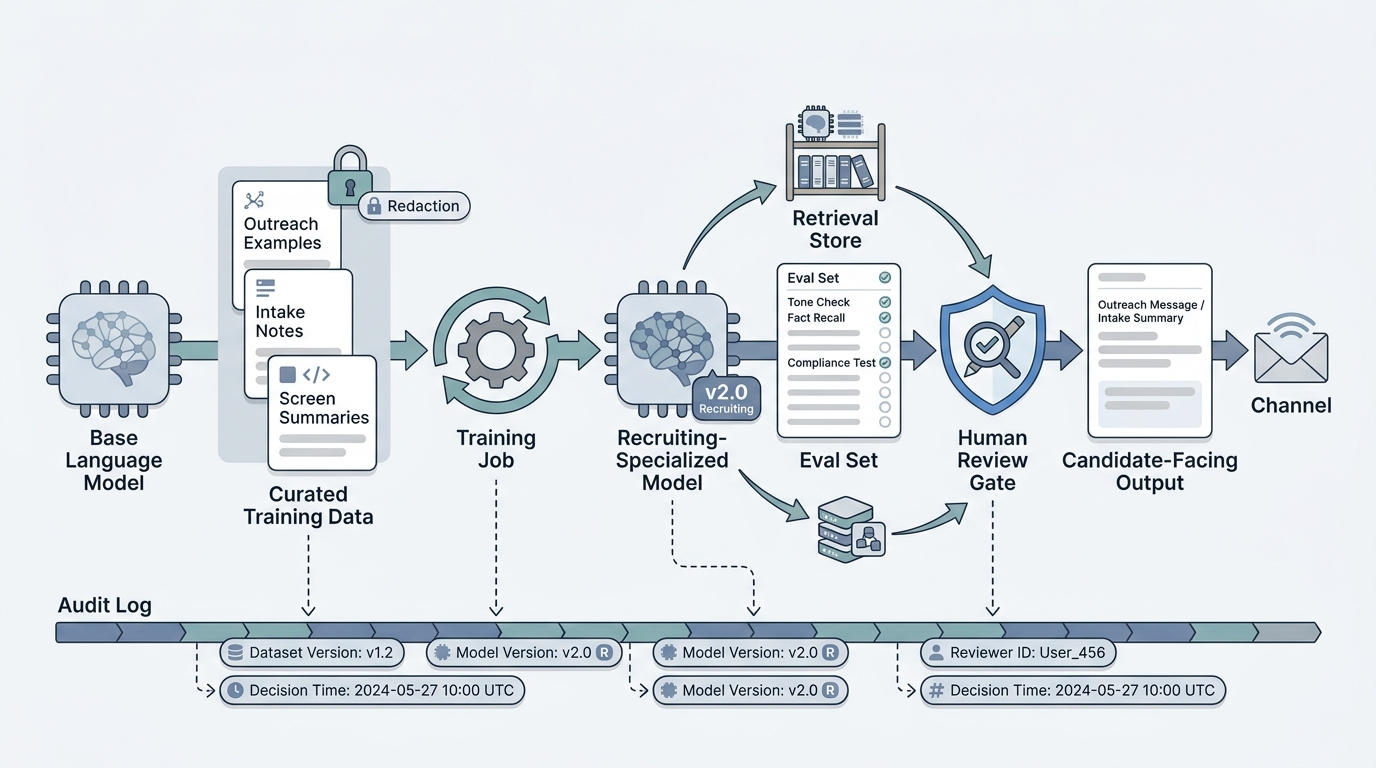
In practice
- A sourcing lead with thousands of intake notes per quarter fine-tunes a small model on a labeled corpus so summaries land in the team's preferred structure without a 400-token system block. The phrase you hear in standups is "we trained the model on our format", not "we wrote a longer prompt".
- TA legal asks vendor demos whether a scoring model was fine-tuned on customer data, how that data was pseudonymized, and whether they can produce per-candidate logs. If the vendor cannot answer, the conversation moves to explainable AI in hiring before the contract is signed.
- A founder building an in-house outreach tool decides retrieval over fine-tuning because the comp bands and JD library change every six weeks. Fine-tuning would freeze a snapshot the team would have to retrain quarterly to keep accurate.
Quick read, then how hiring teams use it
This is for recruiters, sourcers, TA, and HR partners deciding whether to pay for a fine-tune, or evaluating a vendor who already runs one. Skim the first section when you need a shared picture across a hiring team. Use the second when you are working with engineering or a vendor on data, evals, and rollout.
Plain-language summary
- What it means for you: A fine-tuned model has been taught your team's tone and structure during training, so you can ask for shorter prompts and still get on-brand output.
- How you would use it: You collect labeled examples (your good outreach, your preferred intake format), run a training job with a vendor or open-weight tooling, then plug the new model into the same workflow your team already uses.
- How to get started: Write the eval set first: twenty real cases with the answer you would call great. Do not collect training data until you know how you will measure success.
- When it is a good time: When the same task runs hundreds of times a week, prompts have crept past 800 tokens to keep quality, and the underlying criteria have stayed stable for at least a quarter.
When you are running live reqs and tools
- What it means for you: Fine-tuning lives next to retrieval and prompting, not above them. It is the option you reach for last because it costs the most to maintain.
- When it is a good time: High-volume narrow tasks (intake summarization, internal mobility classification, structured screening notes) with stable output shape and rare policy moves.
- How to use it: Build the eval set, redact the training data, label aggressively for tone and structure, train a smaller model first, and benchmark against a strong prompted baseline before you ship.
- How to get started: Read How to write better AI prompts first; if a sharper prompt closes the gap, you do not need a fine-tune yet.
- What to watch for: Stale checkpoints when policy moves, leaked PII from unredacted training data, and silent regressions on tasks the eval set never covered. Pair with human-in-the-loop review on every candidate-facing output.
Where we talk about this
On AI with Michal live sessions, fine-tuning comes up most in sourcing automation when teams ask whether to pay a vendor to train on their corpus or build the workflow with prompting plus retrieval. The honest answer is usually "prompt and retrieve first, fine-tune only the narrowest repeat task". Bring your highest-volume pattern to a Sourcing Lab cohort and we will pressure-test it before you spend a euro on training compute. For ongoing room conversations on sourcing patterns where fine-tuning could earn its place, the AI Sourcing Lab is the right home.
Around the web (opinions and rabbit holes)
Third-party creators move fast. Treat these as starting points, not endorsements, and double-check anything before you wire candidate data into a training job.
YouTube
- Fine-tuning Large Language Models (IBM Technology) is a vendor-neutral primer on what supervised fine-tuning is and when it helps.
- RAG vs Fine-tuning (IBM Technology) is the comparison every TA leader should watch before approving a budget line.
- Let's build GPT: from scratch, in code, spelled out (Andrej Karpathy) is the long-form depth take if you want to understand what training actually changes inside a model.
- When is fine-tuning actually worth it? in r/MachineLearning is a candid practitioner thread on cost versus benefit.
- RAG vs fine-tuning for production use in r/LocalLLaMA covers tradeoffs from people who run both in production.
- How is AI being used in your recruiting process? in r/recruiting includes informal accounts of teams that tried fine-tuning and reverted to prompting.
Quora
- What is fine-tuning in machine learning? gives textbook context; translate to language-model fine-tuning, not classical ML transfer learning.
Fine-tuning versus related customization options
| Approach | When it wins | Watch out |
|---|---|---|
| System instructions | Stable rules, global tone, low cost | Hard limits on length and specificity |
| Few-shot prompting | Tone shift in one thread, fast iteration | Eats LLM tokens, drifts when nobody owns the pack |
| RAG | Facts that move (comp, org chart, JDs) | Retrieval quality dominates everything else |
| Fine-tuning | High-volume narrow task, stable shape | Data labeling, retrains, GDPR scope on weights |
Related on this site
- Glossary: System instructions, Few-shot prompting, RAG, Human-in-the-loop, Explainable AI in hiring, EU AI Act in hiring, Hallucination
- Blog: How to write better AI prompts
- Live cohort: Sourcing Lab
- Lab: AI Sourcing Lab
- Membership: Become a member