AI and ML in recruitment
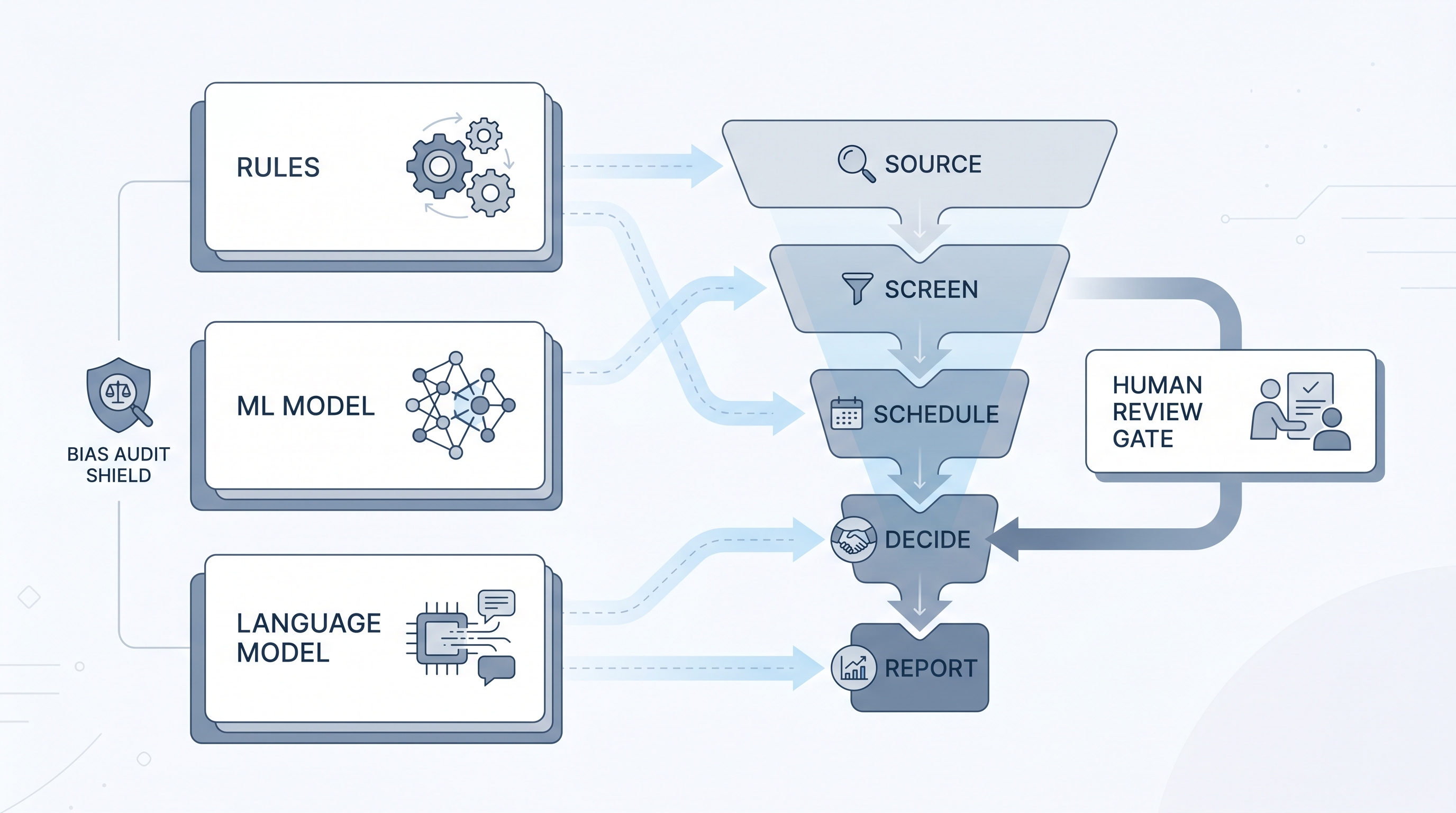
AI in recruitment spans language models, rule-based automation, and machine learning algorithms, each working differently: ML models learn from historical hire data to predict outcomes, while LLMs generate and interpret text. Understanding the difference helps TA teams evaluate vendor tools critically and structure bias audits correctly.
Michal Juhas · Last reviewed May 9, 2026
What is AI and ML in recruitment?
AI and ML in recruitment refers to two overlapping but distinct categories of technology applied across sourcing, screening, scheduling, and reporting in the hiring lifecycle. Machine learning is a subset of AI where systems learn patterns from historical data instead of following hand-coded rules. Language models, the technology behind tools like ChatGPT and Claude, are a further specialisation that reads and generates text.
In a recruiter's daily workflow these distinctions matter. A vendor claiming their tool uses "AI" might mean an ML classifier trained on past hire outcomes, an LLM generating outreach drafts, a simple keyword filter with a marketing label, or some combination. Understanding which mechanism is active at each step determines what questions to ask in a vendor demo, what compliance checks to run, and where to put human review gates.
In practice
- When an ATS vendor says their tool "AI-ranks" candidates, they usually mean an ML model scored resumes by predicted probability of advancing based on past hires at similar companies, a very different mechanism from an LLM that reads a resume and writes a summary.
- A sourcer asking "why did the tool surface these three people?" will get a different answer depending on whether the system uses keyword matching, embedding-based semantic similarity, or a supervised classifier, three mechanisms that look identical in a UI but require different calibration conversations with a hiring manager.
- A TA ops leader saying "the model is biased" and an engineer saying "the model is working as trained" are often both right: ML models encode patterns from labelled historical data, so bias from past decisions becomes a feature until someone audits it.
Quick read, then how hiring teams use it
This is for recruiters, sourcers, TA partners, and HR leaders who need a working vocabulary for vendor conversations, debrief discussions, and audit decisions. Skim the first part for a shared picture. Read the second when you are choosing tools, reviewing contracts, or running an adverse impact check on a model output.
Plain-language summary
- What it means for you: AI in hiring covers at least three different types of technology. Knowing which one a vendor uses helps you ask the right questions and avoid trusting a score that was never calibrated for your roles.
- How you would use it: When evaluating a tool, ask: does this predict from past data, or generate from a language model? Prediction tools need an adverse impact audit. Generation tools need a hallucination review step.
- How to get started: Map the AI in your current ATS and sourcing tools to one of three types: rule-based filter, ML model, or LLM. Then ask each vendor for the last bias audit result or training data date.
- When it is a good time: Before you expand any AI-assisted step to high-volume or high-stakes decisions, not after a compliance question arrives.
When you are running live reqs and tools
- What it means for you: ML models rank or score based on patterns from past hires. LLMs generate text based on broad training corpora. Both can fail silently: a mis-tuned ML model will keep producing confident scores, and an LLM will keep drafting polished text even when key facts are wrong.
- When it is a good time: Use ML-based ranking when volume exceeds what humans can review manually and you have audit infrastructure in place. Use LLM drafting as soon as prompts are stable and outputs pass a human read before touching candidates.
- How to use it: Put a human-in-the-loop gate at every ML decision point where an individual could be rejected. Log the model version and threshold for each run so compliance questions have a paper trail.
- How to get started: Ask your ATS vendor which decisions their AI layer makes versus assists. Get pass-rate data by demographic group before you treat any ML output as a shortlist rather than a starting point.
- What to watch for: Vendors who conflate ML and LLM under a single "AI" label to avoid disclosing training data sources, silent model retraining that changes scoring without notice, and LLM outputs that paste confidently wrong candidate details into ATS records.
Where we talk about this
On AI with Michal live sessions, the distinction between ML models and LLMs comes up in the first hour of every AI in recruiting cohort. The sourcing automation track covers semantic search and embedding-based retrieval as practical alternatives to keyword matching. The AI in recruiting track addresses the compliance landscape for ML-powered vendor tools, including how to read an adverse impact report and what to ask when a vendor says their model is audited. Start at Sourcing Lab and bring your current ATS name and a real role so the room can test the abstractions against something concrete.
Around the web (opinions and rabbit holes)
Third-party creators move fast here. Treat these as starting points, not endorsements, and verify compliance postures and vendor details directly before wiring candidate data to any script you find.
YouTube
- AI Bias and Fairness Explained (IBM Technology) covers algorithmic fairness concepts including adverse impact and group parity, which apply directly to ML-based resume screening tools.
- Introduction to Generative AI (Google Cloud Tech) explains how large language models generate text, useful for understanding why LLM-based tools hallucinate and what guardrails actually do.
- Machine Learning vs Artificial Intelligence vs Deep Learning (Simplilearn) walks the terminology distinctions recruiters encounter in vendor demos without requiring a data science background.
- How are you actually using AI in your recruiting workflow right now? in r/recruiting is a candid practitioner survey of tools and use cases that distinguishes ML-based scoring from LLM-based drafting.
- ML in HR: skeptical of the vendor hype in r/MachineLearning gives a technical view on which HR applications of ML have real evidence behind them versus marketing positioning.
- How do you evaluate AI recruiting tools before buying? in r/recruiting shows the practical questions practitioners ask before signing contracts for ML-powered screening tools.
Quora
- How is machine learning used in recruitment? collects practitioner and researcher perspectives on actual ML deployments in hiring, including failure modes and limitations that vendor demos skip.
AI versus ML versus automation in recruiting
| Technology | What it learns from | Typical use in recruiting | Main risk |
|---|---|---|---|
| Rule-based automation | Nothing, follows fixed logic | ATS routing, email triggers | Mis-mapped fields, silent errors |
| ML model | Historical labelled decisions | Resume ranking, attrition prediction | Bias encoded from past screeners |
| Language model (LLM) | Broad text training corpus | Drafting, summarising, search | Hallucination, stale or wrong facts |
Related on this site
- Glossary: AI in recruiting, AI and hiring, Large language model, Semantic search, Human-in-the-loop, AI bias audit, Adverse impact, Hallucination, Workflow automation, Scorecard
- Blog: AI sourcing tools for recruiters
- Guides: Sourcers
- Workshops: Sourcing Lab
- Courses: Starting with AI: the foundations in recruiting
- Membership: Become a member