Candidate deduplication and merge rules
Logic applied inside an ATS or CRM to detect when two records represent the same candidate and decide which fields to keep, merge, or discard so that sourcing history, application data, and outreach limits are preserved without duplicating contact.
Michal Juhas · Last reviewed May 24, 2026
What is candidate deduplication?
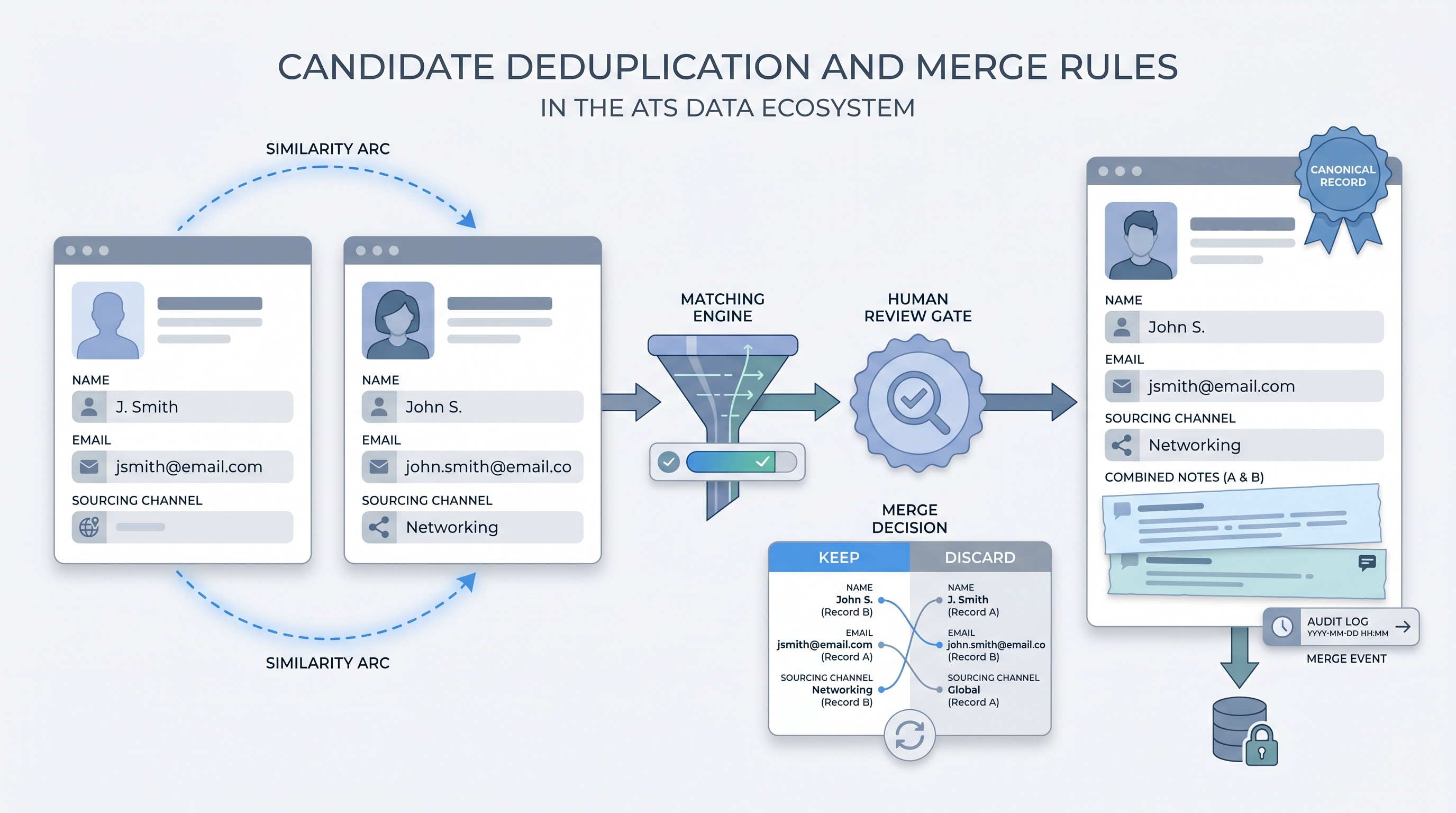
Candidate deduplication is the process of finding and resolving records in your ATS or CRM where the same person appears more than once. Merge rules are the field-level decisions that govern which data survives when two records are combined: whose email address becomes primary, whether notes from both records are preserved, and what happens to the secondary record after the merge completes.
Together these two concepts make up the data hygiene foundation that sourcing analytics, outreach frequency limits, and GDPR compliance all depend on. If a candidate appears twice, every metric that touches that candidate is wrong.
In practice
- A sourcer who sends an outreach message to a candidate, gets no reply, and then accidentally re-sources the same person from a different platform a month later is running into a deduplication failure: the ATS did not recognize the two records as the same person, so the suppression logic did not fire.
- A TA ops team preparing for a GDPR audit discovers that 12 percent of the ATS records are duplicates, which means at least 12 percent of their data subject access request responses are incomplete, because only one of the two records was found and returned.
- A recruiter who runs a pipeline report and sees a candidate appearing in two different stages simultaneously is seeing the visual symptom of a duplicate that was partially progressed on each record independently.
Quick read, then how hiring teams use it
This is for TA ops practitioners, recruiters, and data owners who maintain ATS data quality. Skim the first section for the shared vocabulary. Use the second when you are designing deduplication rules, planning a cleanup project, or building ingestion logic for a new sourcing channel.
Plain-language summary
- What it means for you: When the same person exists twice in your ATS, your outreach limits, stage reports, and candidate history are all wrong. Deduplication finds those pairs; merge rules decide what survives.
- How you would use it: Define the match criteria (email, phone, name plus date of birth, or name plus last employer) and the field-level resolution rules before running any merge. Run a sample of 100 detected pairs through the rules manually before batch-processing thousands.
- How to get started: Export all records with duplicate email addresses from your ATS. That list is your baseline. Every pair on it is a confirmed duplicate. Start merge rules there before tackling the harder fuzzy-name cases.
- When it is a good time: Before an ATS migration, before a GDPR audit, or when sourcing metrics start showing candidates appearing in multiple pipeline stages simultaneously.
When you are running live reqs and tools
- What it means for you: Every new sourcing channel you add increases your duplicate creation rate unless you build deduplication at ingestion. ATS-level deduplication after the fact is far more expensive than a matching check at the API or webhook level.
- When it is a good time: Before you launch a new sourcing integration. If you are wiring recruiting webhooks or API imports from a new tool, add a match-check step that queries the ATS by email and phone before creating a new record.
- How to use it: Write your merge rules into a one-page document: field priority, note concatenation behavior, GDPR implications, and what audit log is created for each merge. Store that document with your ATS configuration so it survives staff changes.
- How to get started: Run a duplicate count query in your ATS (most platforms expose this in admin or analytics). If the duplicate rate is above 5 percent, start a cleanup project. If it is below 5 percent, focus on building ingestion-level deduplication to keep it there.
- What to watch for: Auto-merge tools that do not log what was merged and from which source, false positives where two different candidates share a common name and employer, GDPR deletion requests that only delete one of two duplicate records, and outreach tools that cache email addresses from before a merge and continue suppressing a now-deduplicated record.
Where we talk about this
On AI with Michal live sessions, deduplication surfaces whenever teams connect a new sourcing tool to their ATS and discover that the integration creates new records rather than matching existing ones. In sourcing automation workshops, we wire deduplication logic at the webhook level so the problem does not accumulate. If you want the room conversation, start at Sourcing Lab and bring your current ATS and the sourcing integrations you are running.
Around the web (opinions and rabbit holes)
Third-party creators move fast. Treat these as starting points, not endorsements, and double-check anything before you run batch merges against your ATS.
YouTube
- ATS Data Quality and Deduplication for Recruiting (search) covers practitioner approaches to detecting and resolving duplicate candidate records.
- GDPR and Candidate Data Management in ATS (search) includes compliance-focused walkthroughs of what happens to duplicate records under data subject requests.
- Fuzzy Matching for HR Data Deduplication (search) explains probabilistic matching algorithms in plain language for non-technical TA ops audiences.
- How do you handle duplicate candidates in your ATS? in r/recruiting is a candid thread on what tools actually do versus what vendor demos promise.
- ATS data hygiene before migration in r/humanresources covers what TA ops teams wish they had fixed before moving to a new system.
- GDPR and duplicate candidate records: how do you handle erasure? in r/gdpr addresses the legal questions that most ATS vendor documentation does not answer clearly.
Quora
- How do you deduplicate candidate records in an ATS? collects answers from TA ops practitioners, HRIS specialists, and recruiting technology consultants.
Deduplication approach comparison
| Approach | How it works | Risk |
|---|---|---|
| Exact email match | Flag records with identical email | Misses name-change and multi-email cases |
| Fuzzy name plus employer | Score similarity on name and last company | False positives for common names |
| Embedding similarity | Vector match across full profile text | Opaque scoring, harder to audit |
| Manual review queue | Human reviews all flagged pairs | Slow at scale but lowest false-positive risk |
Related on this site
- Glossary: Recruiting webhooks, Candidate data enrichment, Candidate nurturing, Semantic search, AI browser automation in recruiting, Workflow automation
- Blog: AI sourcing tools for recruiters
- Guides: Sourcers
- Live cohort: Sourcing Lab
- Self-paced: Starting with AI: the foundations in recruiting
- Membership: Become a member