Embeddings in recruiting
Numeric vector representations of text (job descriptions, resumes, notes) that allow AI systems to compare meaning rather than exact words, powering semantic search, similarity scoring, and candidate matching in talent acquisition tools.
Michal Juhas · Last reviewed May 26, 2026
What are embeddings in recruiting?
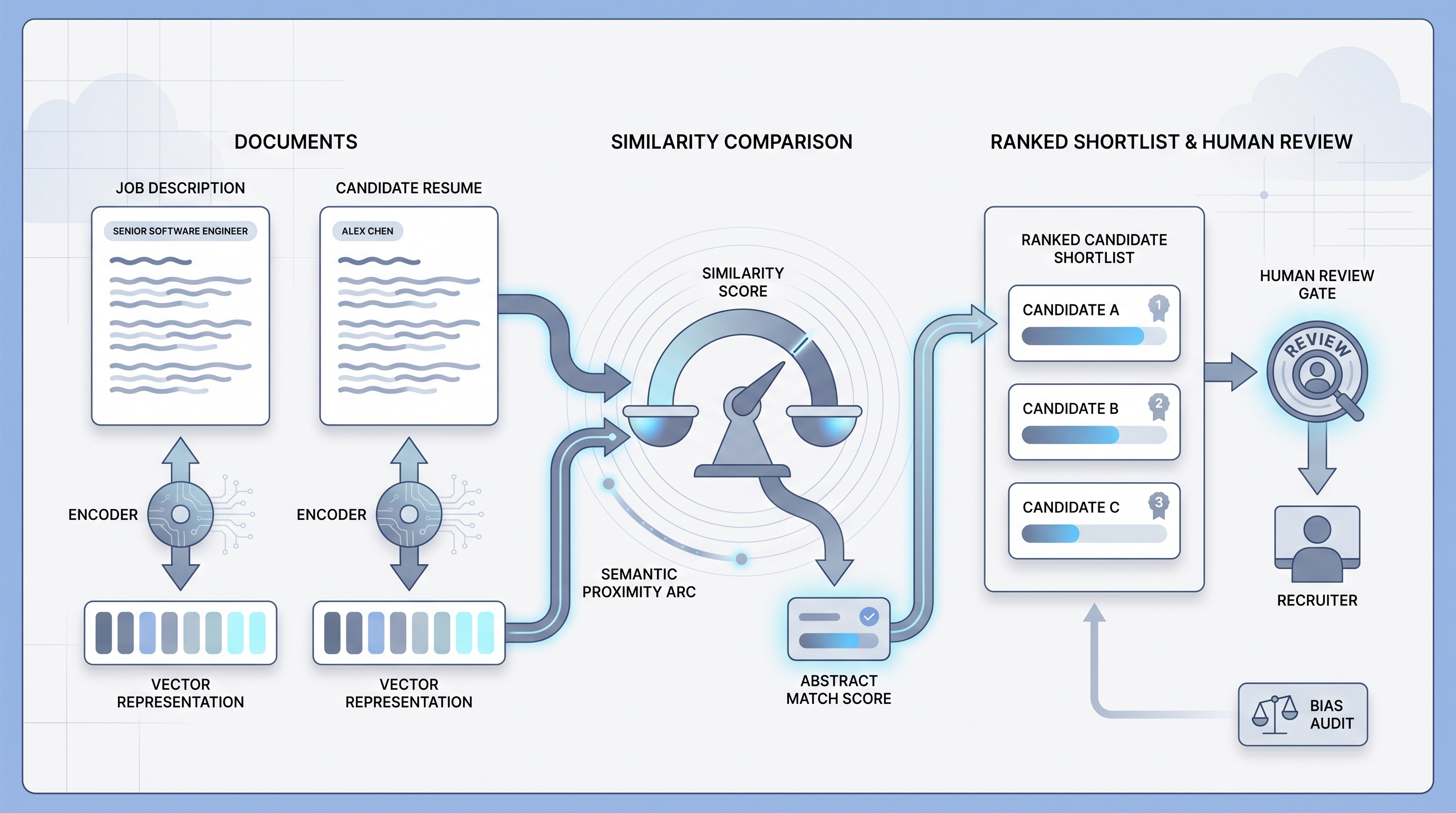
Embeddings are numeric vector representations of text. When you feed a job description or a resume through an embedding model, you get back a list of numbers that encodes the meaning of that text. Two embeddings that are numerically close belong to texts that are semantically similar, even when the exact words differ.
In recruiting, this matters because candidates and job descriptions rarely use identical language. A sourcer searching for a Python developer may miss a strong backend engineer who wrote automation scripts in a different context. Embedding-based tools close that gap by comparing meaning, not just terms.
In practice
- A sourcing platform that surfaces profiles matching your JD even when the resume uses different job titles is running embedding-based similarity under the hood, whether or not the vendor calls it that.
- When an AI assistant searches past interview notes to answer a question about a candidate type, it is typically retrieving the most relevant notes by vector distance, not keyword match.
- A TA ops engineer who says "the model keeps surfacing irrelevant results after we updated our JD templates" may be describing embedding drift: old vectors were generated by a different model version than the current one.
Quick read, then how hiring teams use it
This is for recruiters, sourcers, TA leads, and HR partners who encounter embedding-powered tools in their stack and want a working vocabulary for vendor conversations, bias reviews, and tooling decisions. Skim the first section for a shared mental model. Use the second when you are evaluating a tool, diagnosing inconsistent results, or building a custom workflow.
Plain-language summary
- What it means for you: Embedding-powered tools find matches based on what text means, not just what words appear. That is why your ATS can surface a strong candidate who uses different vocabulary from the JD.
- How you would use it: Evaluate sourcing tools by testing them against edge cases: does the system find candidates with equivalent skills but different title histories? If not, the embedding layer may be weak or the model outdated.
- How to get started: Ask your ATS vendor whether candidate search uses embedding-based or keyword-based retrieval. If embedding-based, ask which model version and when it was last updated.
- When it is a good time: When keyword-based Boolean search is consistently missing good candidates who have the right skills but use different terminology.
When you are running live reqs and tools
- What it means for you: Embedding quality determines how well your AI sourcing tools generalize across role titles, industries, and geographies. A model trained on US tech profiles may not surface equivalent talent in European markets with different title conventions.
- When it is a good time: Before deploying any embedding-based ranking or screening system, run a sample of known good hires through it and measure recall. If the system misses too many, the embeddings need fine-tuning or replacement.
- How to use it: Log which model version generated each embedding. When the vendor updates their model, re-index your candidate records. Keep human-in-the-loop review at every stage where a vector score affects a candidate outcome.
- How to get started: Pull a set of 20 to 30 candidates who were strong hires in a role. Run them through your tool against the current JD. If the embedding-based ranking does not surface most of them in the top results, the system needs calibration before you rely on it.
- What to watch for: Unexplained ranking changes after vendor model updates, demographic skew in embedding-ranked shortlists (run an AI bias audit), and vector databases that were last indexed before a major shift in your job architecture.
Where we talk about this
On AI with Michal live sessions, embeddings come up when sourcing automation participants build custom matching tools or integrate AI into ATS search flows. The questions get practical fast: which model, how to test recall, and what to do when a vendor update breaks a pipeline that worked last month. Start at Sourcing Lab and bring a real sourcing challenge where keyword search has failed you repeatedly. That is where the comparison between keyword and semantic retrieval becomes concrete.
Around the web (opinions and rabbit holes)
Third-party creators move fast. Treat these as starting points, not endorsements, and double-check anything before you wire candidate data to a new tool.
YouTube
- Embeddings Explained for Non-Engineers (search) surfaces accessible walkthroughs of how embeddings work without requiring a machine learning background.
- Semantic Search vs Keyword Search (search) shows the practical difference in retrieval quality on real hiring data.
- Building a RAG System with Embeddings (search) covers how embeddings power the retrieval layer in AI assistants used in recruiting operations.
- Has anyone used embedding search in their ATS? in r/recruiting covers real practitioner experiences with semantic matching tools.
- Bias in AI hiring tools in r/MachineLearning includes technical discussion of how embedding training data shapes downstream hiring tool behavior.
- Vector database comparison in r/vectordatabase covers the infrastructure trade-offs relevant to teams building talent data search.
Quora
- How do AI recruiting tools match candidates to jobs? collects answers from HR tech practitioners explaining the mechanics behind modern candidate matching systems.
Keyword search vs embedding-based search
| Dimension | Keyword search | Embedding-based search |
|---|---|---|
| Match type | Exact term | Semantic proximity |
| Synonym handling | Requires manual OR operators | Automatic via vector distance |
| Explainability | Transparent: shows matched terms | Opaque: shows a similarity score |
| Bias risk | Low if controlled | Higher: inherits model training patterns |
| Best fit | Hard requirements (cert, license) | Broad talent discovery across title variants |
Related on this site
- Glossary: Semantic search, RAG, Human-in-the-loop, AI bias audit, Agent knowledge base
- Blog: AI sourcing tools for recruiters
- Guides: Sourcers
- Live cohort: Sourcing Lab
- Self-paced: Starting with AI: the foundations in recruiting
- Membership: Become a member